Выборочное уравнение регрессии. Выборочная линия регрессии
Что такое регрессия?
Рассмотрим две непрерывные переменные x=(x 1 , x 2 , .., x n), y=(y 1 , y 2 , ..., y n).
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение
, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x , причём изменения в y вызываются именно изменениями в x , мы можем определить линию регрессии (регрессия y на x ), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова "регрессия" исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей "регрессировал" и "двигался вспять" к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x
называется независимой переменной или предиктором.
Y - зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x , т.е. это «предсказанное значение y »
- a - свободный член (пересечение) линии оценки; это значение Y , когда x=0 (Рис.1).
- b - угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b .
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия .
Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a
и b
- выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a
и b
является метод наименьших квадратов
(МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y
- предсказанный y
, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины остаток равен разнице и соответствующего предсказанного Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Остатки нормально распределены с нулевым средним значением;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
"Влиятельное" наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть "влиятельным" наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для "влиятельных" наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению , которая подчиняется распределению с степенями свободы, где стандартная ошибка коэффициента

 ,
,
 - оценка дисперсии остатков.
- оценка дисперсии остатков.
Обычно если достигнутый уровень значимости нулевая гипотеза отклоняется.
![]()
где процентная точка распределения со степенями свободы что дает вероятность двустороннего критерия
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем, мы можем аппроксимировать значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется
, и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации , обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение путем подстановки этого значения в уравнение линии регрессии.
Итак, если прогнозируем как Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Y = b0 + b1 P
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b0 + b1 P2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 (Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 (Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на.40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p<.05 . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на.65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся "внутри диапазона."

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию (-.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p<.001 .
Итог
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Две случайные величины могут быть связаны либо функциональной зависимостью, либо статистической зависимостью, либо быть независимыми. Строгая функциональная зависимость реализуется редко, так как обе или одна из двух величин подвержены еще воздействию случайных факторов. Причем среди этих факторов могут быть и общие для обеих величин, т.е. воздействующие на обе случайные величины. В этих случаях возникает статистическая зависимость.
Статистической называется зависимость, при которой изменение одной из величин влечет изменение распределения другой. В частности, изменение одной из величин вызывает изменение среднего значения другой. В этом случае статистическая зависимость называется корреляционной. Например, связь между количеством удобрений и урожаем, между вложенными средствами и прибылью.
Среднее арифметическое наблюдавшихся значений случайной величины Y , соответствующих значению X=x, называется условным средним x и является точечной оценкой математического ожидания. Аналогично определяется условное среднее y .
Условное математическое ожидание M (Y | x) является функцией отx, следовательно, его оценка, т.е. условное среднее x , также функция от x:
x = f*(x) .
Это уравнение называется выборочным уравнением регрессии Y на X . Функцию f*(x) называют выборочной регрессией , а ее график – выборочной линией регрессии Y на X . Аналогично уравнение
Y = φ * (y),
функцию φ * (y) и ее график называют выборочным уравнением регрессии, выборочной регрессией и выборочной линией регрессии X на Y .
Отыскание параметров функций f*(x) и φ * (y) , если вид их известен, оценка тесноты связи между величинами X и Y – задачи корреляционного анализа. Задачей регрессионного анализа есть оценка параметров функции регрессии β i и остаточной дисперсии σ ост 2 .
Остаточная дисперсия – та часть рассеивания Y , которую нельзя объяснить действием X. σ ост 2 может служить для оценки точности подбора функции регрессии и полноты набора признаков, включенных в анализ. Вид зависимости g(x) выбирают, исходя из характера поля корреляции и природы процесса.
Оценкой коэффициента линейной регрессии β является выборочный коэффициент регрессии Y на X r yx . Значения параметра r yx и параметра b уравнения прямой линии регрессии
Y = r yx x + b
подбираются таким образом, чтобы точки (x 1 ,y 1), (x 2 ,y 2),…,(x n ,y n), построенные по данным наблюдений, на плоскости xOy лежали как можно ближе к прямой линии регрессии. Это равносильно требованию, чтобы сумма квадратов отклонений функции Y(x i) от y i была минимальной. В этом суть МНК.
Выборочное уравнение прямой линии регрессии Y на X может быть записано в таком виде:
x – = r в s y /s x (x – ) ,
где s x и s y – выборочные средние квадратические отклонения X и Y , а
r в =  –
–
выборочный коэффициент корреляции, вычисленный по сгруппированным данным. Здесь n xy – частота пары вариант (x,y). Аналогично находят выборочное уравнение прямой линии регрессии X на Y:
Y – = r в s x /s y (y – )
Для того, чтобы установить, соответствует ли найденная по выборке математическая модель зависимости между Y и X статистическим данным, следует оценить значимость коэффициентов регрессии и значимость уравнения регрессии.
Проверить значимость коэффициентов регрессии означает установить, достаточна ли величина оценки для обоснованного вывода о том, что коэффициент регрессии отличен от нуля. Выдвигают гипотезу H 0: коэффициент регрессии равен нулю β =0. Проверку гипотезы H 0 осуществляют с помощью распределенной по закону Стьюдента статистики
t = │b / s b │
где b – оценка коэффициента регрессии, а s b – оценка его среднего квадратического отклонения, другими словами стандартная ошибка оценки. Если │t │≥ t кр (α, k), нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, и коэффициент считают значимым. При │t │< t кр нет оснований отвергать нулевую гипотезу.
Титульный лист методических Форма
Министерство образования и науки Республики Казахстан
«
Председатель УМС _______________ « ___»___________20__ г.
ОДОБРЕНО:
Начальник ОПиМОУП _________________ « ___»___________20__ г.
Одобрена учебно-методическим советом университета
« ___»___________20 __г. Протокол №____
При изучении темы « Сведения из теории вероятностей и математической статистики» особое внимание следует обратить способы представления и обработки статистических данных. Теоретические и выборочные характеристики. Общая схема проверки гипотез. Ошибки 1 и 2 рода. Точечные и интервальные оценки. Статистические свойства оценок. Анализ зависимостей двух случайных величин.
Тема. Метод наименьших квадратов.
h1 , h2 – шаги, т. е. разности между двумя соседними вариантами.
В этом случае выборочный коэффициент корреляции
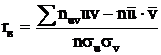 ,
,
причем слагаемое удобно вычислять, используя расчетную таблицу 1.
Величины могут быть найдены по формулам
Для обратного перехода применяются выражения
Пример Найти выборочное уравнение линейной регрессии Y на X на основании корреляционной таблицы.
Решение. Для упрощения расчетов перейдем к условным вариантам, которые рассчитываются по формулам
, 
и составим преобразованную корреляционную таблицу с условными вариантами
Затем составим новую таблицу, в которую внесем посчитанные значения в правый верхний угол заполненной клетки и в левый нижний угол, после чего суммируем верхние значения по строкам для получения значений Vj и нижние значения по столбцам для Ui и подсчитаем величины и .
vjVj |
||||||||
Выражается через выборочные значения (а, 7),
Теперь обратимся к выборочным данным о расходах, собранным путем выборочного опроса части жителей городка. Считая выборку репрезентативной , предположим, для простоты, она включает по одному человеку из каждой группы дохода. Отображая выборочные точки на графике, мы можем провести через них линию регрессии , соответствующую уравнению Y = а + ЬX, коэффициенты а и b в котором рассчитываются по обычным формулам линейной регрессии . Если учесть, что наблюдаемые значения К. не лежат на линии регрессии (a+bXt), то в это уравнение надо добавить выборочные случайные возмущения е (ek = Yk-a-bX , являющиеся аналогами случайных возмущений в генеральной совокупности
Он характеризует долю вариации (разброса) зависимой переменной , объясненной с помощью данного уравнения. В качестве меры разброса зависимой переменной обычно используется ее дисперсия, а остаточная вариация может быть измерена как дисперсия отклонений вокруг линии регрессии . Если числитель и знаменатель вычитаемой из единицы дроби разделить на число наблюдений л, то получим, соответственно, выборочные оценки остаточной дисперсии и дисперсии зависимой переменной . Отношение остаточной и общей дисперсий представляет собой долю необъясненной дисперсии. Если же эту долю вычесть из единицы, то получим долю дисперсии зависимой переменной , объясненной с помощью регрессии. Иногда при расчете коэффициента детерминации для получения несмещенных оценок дисперсии в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы тогда
Требуется по полученным данным найти выборочное уравнение прямой линии средней квадратической регрессии
Из рис. 16.8 видно, что выборочные линии регрессии имеют разный наклон и разные точки пересечения с осью У для различных выборок. Более того, при положительном наклоне генеральной регрессии наклон выборочной линии регрессии может оказаться для некоторых выборок отрицательным, что, однако, не будет свидетельствовать об истинной отрицательной связи исследуемых величин. Для того чтобы убедиться в этомт следует помимачюэффици-ентов регрессии находить их стандартные отклонения и f-статисти-ки, по которым можно судить о статистической значимости полученных выборочных коэффициентов регрессии.
Реальная трудность применения рассмотренного метода состоит в отыскании переменных, пригодных для роли инструментальных. Истинное распределение ненаблюдаемо и поэтому трудно быть уверенным в том, что выбранные инструментальные переменные действительно не коррелируют в пределе с возмущениями. С другой стороны, эти переменные должны обладать довольно высокой корреляцией с переменными X, иначе выборочные дисперсии для оценок, полученных с помощью
При большом числе испытаний одно и то же значение X может встретиться nx раз, одно и то ж значение У может встретиться ny раз и одна и та же пара чисел (x; у) может встретиться nxy раз,
причем обычно— объем выборки.
Поэтому данные наблюденийГруппируют, т. е. подсчитывают nx, ny, nxy. Все сгруппированные данные записывают в виде таблицы, которую называют корреляционной.
Если обе линии регрессии У на X и X на У — прямые, то корреляция является линейной.
Выборочное уравнение прямой линии регрессии У на X имеет вид:

Параметры pyx и В, которые определяются методом наименьших квадратов, имеют вид:
где yx — условная средняя; XВ и Ув — выборочные средние признаков X и У; —x и —у — выборочные средние квадратические отклонения; гВ — выборочный коэффициент корреляции.
Выборочное уравнение прямой линии регресии X на У имеет вид:

Считаем, что данные наблюдений над признаками X и У заданы в виде корреляционной таблицы с равноотстоящими вариантами.
Тогда переходим к условным вариантам:

где С1 — варианта признака X, имеющая наибольшую частоту; С 2 — варианта признака У, имеющая наибольшую частоту; h1 — шаг (разность между двумя соседними вариантами X); h2 — шаг (разность между двумя соседними вариантами У).
Тогда выборочный коэффициент корреляции

Величины u, v, su, sv могут быть найдены методом произведений, либо непосредственно по формулам
Зная эти величины, найдем параметры, входящие в уравнения регрессии, по формулам
ТИПОВЫХ КОНТРОЛЬНОЙ РАБОТЫ ПО РАЗДЕЛУ 6. 12.1. Случайные события
12.1. Случайные события
12.1.1. В ящике находятся 6 одинаковых пар перчаток черного цвета и 4 одинаковых пары перчаток бежевого цвета. Найти вероятность того, что две наудачу извлеченные перчатки образуют пару.
Рассмотрим событие А — две извлеченные наудачу перчатки образуют пару; и гипотезы: B1 — извлечена пара перчаток черного цвета, B2 — извлечена пара перчаток бежевого цвета, B3 — извлеченные перчатки пару не образуют.
Вероятность гипотезы B1 по теореме умножения равна произведению вероятностей того, что первая перчатка черного цвета и вторая перчатка черного цвета, т. е.
Аналогично, вероятность гипотезы Bi равна:
Так как гипотезы B1, B2 и B3 составляют полную группу событий, то вероятность гипотезы B3 равна:
По формуле полной вероятности имеем:
где Pb (A) есть вероятность того, что пару образуют две черные перчатки и Pb1 (A) = 1; pB1 (A) — вероятность того, что пару образуют две бежевые перчатки и Pb2 (A) = 1; и, наконец, РВз(A) — вероятность того, что пару образуют перчатки разного цвета и

Таким образом, вероятность того, что две наудачу извлеченные перчатки образуют пару равна
12.1.2. В урне находятся 3 шара белого цвета и 5 шаров черного цвета. Наудачу по одному извлекают 3 шара и после каждого извлечения возвращают обратно в урну. Найти вероятность того, что среди извлеченных шаров окажется:
а) ровно два белых шара, б) не мене двух белых шаров.
Решение. Имеем схему с возвращением, т. е. каждый раз состав шаров не изменяется:
а) при извлечении трех шаров два из них должны быть белыми, а один черный. При этом черный может оказаться или первым, или вторым, или третьим. Применяя совместно теоремы сложения и умножения вероятностей, имеем:

б) вынуть не менее двух белых шаров означает, что белых шаров должно быть или два, или три:

12.1.3. В урне находятся 6 белых и 5 черных шаров. Три шара наудачу последовательно извлекаются без возвращения их в урну. Найти вероятность, что третий по счету шар окажется белым.
Решение. Если третий по счету шар должен быть белым, то первые два шара могут быть белыми, или белым и черным, или черным и белым, или черными, т. е. имеются четыре группы не-
совместных событий. Применяя к ним теорему умножения вероятностей, получим:
P = P1(5 . P2(5 . P3(5 + (P1(5 . Р2ч. P3(5 + P14 . P2(5 . P3(5) + Р1ч. Р2ч. P3(5 =
A A 4 A A 5 A A 5 A A 6=540 = A
П. 10 . 9 + И. 10 . 9 + И. 10 . 9 + И. 10 . 9 = 990 = IT




