Парная регрессия и корреляция. Уравнение нелинейной регрессии
Федеральное государственное образовательное учреждение
высшего профессионального образования
«СИБИРСКИЙ ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ»
Институт управления бизнес-процессами и экономики
Кафедра теоретические основы экономики
Лабораторная работа № 2
по курсу эконометрика
(Вариант 6,7)
Руководитель _______________ Середа В.А.
подпись, дата
Студентка, УБ11-01 _______________ Ивкина В.А.
подпись, дата
Красноярск 2013
Введение……………………………………….…………………………………..3
1.Линейное уравнение регрессии 5
2.Показательное уравнение регрессии 7
3.Логарифмическое уравнение регрессии 9
Логарифмическое уравнение регрессии определяется по формуле: 9
Получим логарифмическое уравнение регрессии: 9
5.Поверка значимости уравнения регрессии и отдельных коэффициентов линейного уравнения 13
6.Построение интервального прогноза для значения x = xmax по уравнению линейной регрессии 17
7.Средний коэффициент эластичности 20
Цель работы: Закрепить навыки построения уравнений регрессии, графиков уравнений, вычисления оценок и построения доверительных интервалов для уравнений регрессии.
Построить уравнения регрессии, включая линейную регрессию
Вычислить индексы парной корреляции для каждого уравнения
Проверить значимость уравнений регрессии и отдельных коэффициентов линейного уравнения
Определить лучшее уравнение регрессии на основе средней ошибки аппроксимации
Построить интервальный прогноз для значения x=x max для линейного уравнения регрессии
Определить средний коэффициент эластичности
Исходные данные:
|
Области и республики |
Холодильники. Морозильники.(X ) |
Стиральные машины.(Y) |
|
Белгородская область | ||
|
Брянская область | ||
|
Владимирская область | ||
|
Воронежская область | ||
|
Ивановская область | ||
|
Калужская область | ||
|
Костромская область | ||
|
Курская область | ||
|
Липецкая область | ||
|
Московская область | ||
|
Орловская область | ||
|
Рязанская область | ||
|
Смоленская область | ||
|
Тамбовская область | ||
|
Тверская область | ||
|
Тульская область | ||
|
Ярославская область | ||
|
Республика Карелия | ||
|
Республика Коми | ||
|
Архангельская область | ||
|
Вологодская область | ||
|
Калининградская область | ||
|
Ленинградская область | ||
|
Мурманская область | ||
|
Новгородская область | ||
|
Псковская область | ||
|
Краснодарский край | ||
|
Ставропольский край | ||
|
Астраханская область | ||
|
Волгоградская область | ||
|
Ростовская область | ||
|
Республика Башкортостан | ||
|
Республика Марий Эл | ||
|
Республика Мордовия | ||
|
Республика Татарстан | ||
|
Удмуртская Республика | ||
|
Чувашская Республика | ||
|
Кировская область | ||
|
Нижегородская область | ||
|
Оренбургская область | ||
|
Пензенская область | ||
|
Пермская область | ||
|
Самарская область | ||
|
Саратовская область | ||
|
Ульяновская область |
Линейное уравнение регрессии
Формула линейного уравнения регрессии (1)
x,y – переменные,
a,b – параметры.
Система нормальных уравнений (2) в общем виде:
 (2)
(2)
n - количество наблюдений в совокупности.
Система нормальных уравнений с вычисленными коэффициентами:
![]()
Решение системы:
Построенное линейное уравнение регрессии:

Рис. 1 График линейного уравнения регрессии
Показательное уравнение регрессии
Показательное уравнение регрессии имеет следующий вид:
![]() ,
,
 ,
,
x,y – то же что и в формуле (1),
Найдем b 0 и b 1:
Полечим показательное уравнение регрессии:
Логарифмическое уравнение регрессии
Логарифмическое уравнение регрессии определяется по формуле:
x,y – то же что и в формуле (1),
b – то же что и в формуле (1),
![]() ,
,
 (8),
(8),
x,y – то же что и в формуле (1),
b – то же что и в формуле (1),
n – то же что и в формуле (2).
Найдем b 0 и b 1:
Получим логарифмическое уравнение регрессии:

Рис. 1 График логарифмического уравнения регрессии
Индекс парной корреляции для уравнений регрессии
Индекс парной корреляции исчисляется по следующей формуле:
 (9)
(9)
y – то же что и в формуле (1),
–значение у из исследуемого уравнения,
Среднее значение y.
Для оценки качества построенной модели регрессии можно использовать индекс детерминации или среднюю ошибку аппроксимации. Чем выше показатель детерминации или чем ниже ошибка аппроксимации, чем лучше модель описывает исходные данные.
Средняя ошибка аппроксимации – среднее относительное отклонение расчетных значений от фактических, рассчитывается по формуле
![]() (10)
(10)
y – то же что и в фотрмуле (1).
Индекс парной корреляции для линейного уравнения регрессии:
![]() =
0,92
=
0,92
Средняя ошибка аппроксимации для линейного уравнения регрессии:
![]() =6%
=6%
Индекс парной корреляции для логарифмического уравнения регрессии:
![]() =0,95
=0,95
Средняя ошибка аппроксимации для логарифмического уравнения регрессии:
![]() =6%
=6%
Построенные уравнения считаются удовлетворительными, так как . Коэффициент детерминации достаточно высокий, а это значит, что модель точно описывает исходные данные.
Поверка значимости уравнения регрессии и отдельных коэффициентов линейного уравнения
Оценка статистической значимости уравнения регрессии в целом осуществляется с помощью F -критерия Фишера.
Величина F факт определяется по формуле:
 (11)
(11)
Индекс детерминации,
n – то же что и в формуле (2),
m – число параметров при переменных.
Таким образом, для
F факт
=
 =2,26
=2,26
F крит =4,08, при α =0,05
F табл >
 =3,87
=3,87
F крит =4,08, при α =0,05
F табл >F факт, гипотеза H 0 не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов линейной регрессии применяется t- критерий Стьюдента:
Величины t b ,факт и t a , факт определяются по формулам:
a,b – то же что и в формуле (1),
r xy - коэффициент корреляции,
m b , m a , m rxy – стандартные ошибки.
Таким образом, для
линейного уравнения регрессии:
логарифмического уравнения регрессии:
Стандартные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
 (15)
(15)
 (16)
(16)
Где, y – то же что и в формуле (1),
–то же что и в формуле (9),
То же что и в формуле (9),
1. Построим уравнения степенной нелинейной регрессии вида для пар переменных y, x.
Нахождение модели парной регрессии сводится к оценке уравнения в целом и по параметрам (b0, b1). Для оценки параметров однофакторной модели используют метод наименьших квадратов (МНК). В МНК получается, что сумма квадратов отклонений фактических значений показателя у от теоретических ух минимальна
Сущность нелинейных уравнений заключается в приведении их к линейному виду и как при линейных уравнениях решается система относительно коэффициентов b0 и b1.


Рисунок 3 Линия регрессии на корреляционном поле. Ось ординат - значения y(Производительность труда), ось абсцисс -значения x (Удельный вес рабочих в составе ППП)

Рисунок 4 Линия регрессии на корреляционном поле. Ось ординат - значения y(степ.функция), ось абсцисс -значения x (Удельный вес рабочих в составе ППП)
Найдем среднюю относительную ошибку аппроксимации по формуле:

Полученное значение между 20% и 50%, что свидетельствует о существенности удовлетворительного отклонения расчетных данных от фактических, по которым построена эконометрическая модель.
Исследование статистической значимости уравнения регрессии в целом проводится с помощью F-критерия Фишера. Расчетное значение критерия находится по формуле:

Для парного уравнения p = 1.
Табличное (теоретическое) значение критерия находится по таблице критических значений распределения Фишера-Снедекора по уровню значимости по уровню значимости б и двум числам степеней свободы k1 = p = 1 и k2 = n - p - 1 = 51.
Если Fрасч то гипотеза принимается, а уравнение линейной регрессии в целом считается статистически незначимым (с вероятностью ошибки 5%).Для уравнения Fрасч = 0,01609). Неравенство выполняется. Уравнение в целом статистически незначимо. Теснота нелинейной корреляционной связи определяется с помощью корреляционных отношений (индекс корреляции). Инструкция
. Укажите количество исходных данных. Полученное решение сохраняется в файле Word
. Также автоматически создается шаблон решения в Excel
.
Уравнению регрессии первого порядка
- это уравнение парной линейной регрессии . Уравнение регрессии второго порядка
это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
Уравнение регрессии третьего порядка
соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания): Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии
. Получим таблицу следующего вида.
Степенное уравнение регрессии имеет вид y = a x b
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Показательное уравнение регрессии имеет вид y = a b x + ε
Экономическая интерпретация коэффициентов регрессии в целом является завершающим этапом эконометрического моделирования на основе совокупности исходных данных. В данном случае экономическая интерпретация - это объяснение смысла, содержания полученных коэффициентов регрессии. На экономическую интерпретацию коэффициентов регрессии оказывают влияние такие факторы, как сфера экономики, для которой строится эконометрическая модель, количество исходных данных (объем совокупности) для анализа изучаемого явления и т.п. Одним из важнейших факторов интерпретации коэффициентов регрессии является вид полученной модели. Линейное уравнение регрессии
имеет вид y = bx + a + ε Здесь ε - случайная ошибка (отклонение, возмущение). Коэффициент множественной регрессии bj
показывает, на какую величину в среднем изменится результативный признак Y
, если переменную Xj
увеличить на единицу измерения, т. е. является нормативным коэффициентом. Параметр а = у, когда х = 0. Если х не может быть равен 0, то а не имеет экономического смысла. Интерпретировать можно только знак при а: если а > 0. то относительное изменение результата происходит медленнее, чем изменение фактора, т. е. вариация результата меньше вариации фактора: V < V. и наоборот. В линейной множественной регрессии коэффициенты при хi характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменных значениях других факторов, закреплённых на среднем уровне. При изучении вопросов потребления коэффициенты регрессии рассматриваются как характеристики предельной склонности к потреблению. Например, если функция потребления Сt имеет вид Сt = b0 + b1* Rt + b2* Rt-1 +epsilont, то потребление за t-й период времени зависит от дохода того же периода Rt и от дохода предшествующего периода Rt-1. Соответственно, коэффициент b1 характеризует эффект от единичного возрастания дохода Rt при неизменном уровне предыдущего дохода. Коэффициент b1 обычно называют краткосрочной предельной склонностью к потреблению. Общим эффектом возрастания как текущего, так и предыдущего дохода будет рост потребления на величину b = b1+b2. Коэффициент b рассматривается здесь как долгосрочная предельная склонность к потреблению. Уравнение парной степенной модели имеет вид: у = а х^b В уравнении парной степенной регрессии параметр b показывает: на сколько процентов изменится результативный показатель, при изменении фактора на /%, то есть является коэффициентом эластичности. Знак при коэффициенте регрессии указывает направление связи между фактором и результативным показателем: если Ь>0, следовательно, связь прямая и с увеличением значения фактора (х) возрастает и значение результативного показателя (у); если Ь<0, следовательно, связь обратная и с увеличением значения фактора (х) снижается значение результативного показателя.Таким образом, при увеличении расходов на конечное потребление на 1 %, в среднем доля расходов на питание снижается на 0,5. Таким образом, получили, что показатели степени при переменных в мультипликативной степенной модели являются соответствующими коэффициентами эластичности. Это важное свойство степенных моделей. Экспоненциальная
регрессия
имеет вид ŷ
= е
aх
+ b
(или ŷ
=
ba
х
);
(24) степенная
регрессия
имеет вид ŷ
= bх
а
;
(25) Для нахождения коэффициентов а
иb
предварительно проводят процедуру
линеаризации выражений (24) и (25): lnŷ
=lnb+
x
lnа,
(26) lnŷ
=lnb
+а
lnx
,
(27) а
затем уже строят линейную регрессию
между lnŷ
и х
для экспоненциальной регрессии,
и между lnŷ
и lnх
для степенной регрессии.
Наибольшее
распространение степенной функции в
эконометрике связано с тем, что параметр
а
имеет четкое экономическое истолкование,
– он является коэффициентом эластичности.
Это значит, что коэффициент b
показывает, на сколько % в среднем
изменится результат, если фактор
изменится на 1%. Для
вычисления параметров экспоненциальной
регрессии (24) на компьютере
используется
встроенная статистическая функция
ЛГРФПРИБЛ
.
Порядок вычисления аналогичен применению
функции ЛИНЕЙН
. Для
вычисления параметров степенной
регрессии
после преобразования исходных данных
в соответствие с (27), можно воспользоваться
функцией ЛИНЕЙН.
Для
получения графиков однофакторных
регрессий можно применить Мастер
диаграмм
,
строя предварительно непрерывный или
точечный график исходных данных
(диаграмму рассеяния), а затем использовать
режим Добавить
линию тренда
,
причем в этом режиме Excel
предоставляет
возможность выбора шести функций –
линейной, логарифмической, полиномиальной,
степенной, экспоненциальной и скользящей
средней. После выбора функции в режиме
Параметры
задайте флажок Показывать
уравнение на диаграмме
и Поместить
на диаграмму величину достоверности
аппроксимации(
R
^2)
. Методы
математической статистики широко
применяются для анализа экономических
временных рядов
. В общем случае
временной ряд содержит детерминированную
и случайную составляющие: у
t =f(t,х
t)+ t ,
t=1,…,Т, гдеу
t
– значения
временного ряда; f(t,х
t)
– детерминированная составляющая; х
t
– значения факторов, влияющих на
детерминированную составляющую в момент
t; t
– случайная составляющая; Т – длина
ряда. Получив оценки
детерминированной и случайной
составляющих, решают задачи прогноза
будущих значений, как самого временного
ряда, так и его составляющих. Если
детерминированная составляющая зависит
только от времени и линейна относительно
своих параметров, то задача сводится к
задаче множественной линейной регрессии,
рассмотренной выше. Действительно, в
этом случае у
t = 0 + 1
1 (t) + 2
2 (t) +…+ m
m (t)+ t ,
t=1,…,Т. (28) В частном случае, у
t = 0 + 1 t 1
+ 2 t 2
+…+ m t m
+ t ,
t=1,…,Т. (29) Детерминированная
составляющая в свою очередь представляется
тремя составляющими. Долговременная
эволюторно изменяющаяся составляющая
является результатом действия факторов,
приводящих к постепенному изменению
экономического показателя. Так, в
результате научно-технического прогресса,
совершенствования системы управления
производством показатели эффективности
производства растут, а удельные расходы
на единицу полезного эффекта снижаются. Долговременная
циклическая составляющая
проявляется
на протяжении длительного времени в
результате действия факторов, обладающих
большим последействием или циклически
изменяющихся во времени. Например,
кризисы перепроизводства или периодичность
солнечной активности, влияющая на
урожайность. Сезонная
циклическая составляющая
легко просматривается в колебаниях
продуктивности сельскохозяйственных
животных, а также в колебаниях розничного
товарооборота в зависимости от времени
года. Многие
исследователи первую составляющую
называют трендом
,
другие трендом называют все три
составляющие. Эволюторно
изменяющуюся долговременную составляющую
во многих практических случаях
представляют в виде некоторой аналитической
функции (см. ниже), тогда как долговременная
и сезонная циклические составляющие
представляются тригонометрическими
трендами
. Для построения
эволюторных трендов (моделирования
тенденции) чаще всего применяются те
же функции, которые мы рассматривали
выше: линейный
тренд: ŷ
t =b
+
at
; гипербола:
ŷ
t =
b+a
/t
; экспоненциальный
тренд: ŷ
t =
е
b+
a
t
(или ŷ
t =ba
t
); тренд
в форме степенной функции ŷ
t =
b
t
a
; полином
порядка m:
ŷ
t =
b +
a
1 t
+ a
2 t
2
+…+ a
m
t
m . Параметры
каждого из перечисленных выше трендов
можно определить обычным МНК, используя
в качестве независимой переменной время
t. Для нелинейных трендов предварительно
проводят процедуру их линеаризации. Пример
6
. Имеются
помесячные данные о темпах роста
заработной платы в РФ за 10 месяцев 2004
г. в процентах к уровню декабря 2003г.
(табл. 10). Требуется выбрать наилучший
тип тренда и определить его параметры. Таблица
10 Определим параметры
основных видов тренда. Результаты этих
расчетов представлены в табл. 11. Таблица
11 Наилучшей
является степенная форма тренда, которая
в исходном виде (после потенцирования)
примет следующий вид ŷ
t =
е
4.39
t
0,193 или
ŷ
t =
80,32t
0,193 . Наиболее простую экономическую
интерпретацию имеют параметры линейного
и экспоненциального трендов. Параметры линейного тренда можно
интерпретировать так: b
– начальный
уровень временного ряда при t
=0; a
– средний за период абсолютный прирост
ряда. Применительно
к примеру 6 можно сказать, что темпы
роста месячной заработной платы за 10
месяцев 2004г. изменялись от 82,66% со средним
за месяц абсолютным приростом 4,72%. Параметры экспоненциального тренда
имеют следующую интерпретацию: b
– начальный уровень временного ряда
при t
=0; е
a
–
средний за период коэффициент роста
ряда. В примере 6 уравнение
экспоненциального тренда в исходной
форме имеет вид ŷ
t =
е
4.43
е
0,045 t
или
ŷ
t =
83,96е
0,045 t
. Следовательно,
можно сказать, что темпы роста месячной
заработной платы за 10 месяцев 2004г.
изменялись от 83,96% со средним за месяц
темпом роста, равным е
0,045 =
1,046. Моделирование
сезонных и циклических колебаний.
Общий вид модели (аддитивной) следующий: где
Т – трендовая, S
– сезонная и Е – случайная компонента. S может моделироваться
с помощью тригонометрических функций,
однако можно обойтись и более простым
способом, суть которого разберем на
простом примере. Пример
7.
Пусть
известны объемы потребления электроэнергии
жителями района за четыре года (табл.12). Таблица 12 № квартала Потребление
электроэнергии Итого за 4 квартала Скользящая
средняя за 4 квартала Центрированная
скользящая средняя Оценка сезонной
компоненты Данный временной ряд содержит сезонные
колебания периодичностью 4 (объемы
потребления электроэнергии в осенне-зимний
период выше, чем весной и летом). Шаг
1.
Проведем
выравнивание исходных данных методом
скользящей средней. Для этого: а)
просуммируем у
t
последовательно за каждые 4 квартала
со сдвигом на один (гр.3 табл. 12); б) разделив эти
суммы на 4, найдем скользящие средние
(гр.4 табл. 12); в) приведем эти
значения к соответствующим кварталам,
для чего найдем средние значения из
двух последовательных скользящих
средних – центрированные скользящие
средние (гр. 5 табл.12). Шаг
2.
Найдем
оценки сезонной компоненты (гр.6 табл.
12). Найдем средние за каждый квартал
оценки сезонной компоненты Š 1 =(0,575+0,55+0,675)/3=0,6; Š 2 =(–2,075
– 2,025 – 1,775)/3= –1,958; Š 3 =(–1,25
– 1,1 – 1,475)/3= –1,275; Š 4 =(2,55+2,7+2,875)/3=2,708. Сумма
значений сезонной компоненты по всем
кварталам должна быть равна нулю, а у
нас получилось 0,6 – 1,958 – 1,275 + 2,7=0,075,
поэтому определяем корректирующий
коэффициент k=0,075/4=0,01875.
Окончательно определяем сезонную
компоненту S i
= Š i
– k. Таким образом,
получаем S 1
=0,581; S 2
= –1,979; S 3
= –1,294; S 4
=2,69. Занесем полученные
значения в табл.13 для соответствующих
кварталов (гр.3). Таблица
13 T+E=
y
t
– S t Шаг
3
. Вычисляем
T+E=
y
t
– S t
(гр.4 табл.13). Шаг
4.
По данным
графы 4 строим линейный тренд Т=5,715 +
0,186t
.
Подставляя в это уравнение t
=1,2,…16,
находим Т (гр. 5 табл.13). Шаг
5
. Находим
теоретические значения T+S
(гр. 6 табл. 13). Шаг
6.
Вычисляются
ошибки модели и их квадраты (гр. 7 и 8
табл.13).
Ограничить однородную совокупность единиц, устранив аномальные объекты наблюдения можно через метод Ирвина или по правилу трех сигм (устранить те единицы, для которых значение объясняющего фактора отклоняется от среднего более, чем на утроенное среднеквадратичное отклонение).
Виды нелинейной регрессии
Здесь ε - случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.

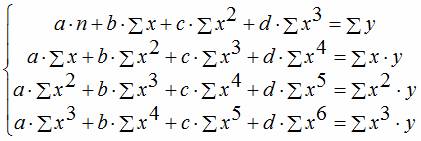
Пример
. По данным, взятым из соответствующей таблицы, выполнить следующие действия:
y = f(x)
Преобразование
Метод линеаризации
y = b x a
Y = ln(y); X = ln(x)
Логарифмирование
y = b e ax
Y = ln(y); X = x
Комбинированный
y = 1/(ax+b)
Y = 1/y; X = x
Замена переменных
y = x/(ax+b)
Y = x/y; X = x
Замена переменных. Пример
y = aln(x)+b
Y = y; X = ln(x)
Комбинированный
y = a + bx + cx 2
x 1 = x; x 2 = x 2
Замена переменных
y = a + bx + cx 2 + dx 3
x 1 = x; x 2 = x 2 ; x 3 = x 3
Замена переменных
y = a + b/x
x 1 = 1/x
Замена переменных
y = a + sqrt(x)b
x 1 = sqrt(x)
Замена переменных
Год
Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. - трлн. руб.), y
Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. - тыс. руб.), х
1995
872
515,9
2000
3813
2281,1
2001
5014
3062
2002
6400
3947,2
2003
7708
5170,4
2004
9848
6410,3
2005
12455
8111,9
2006
15284
10196
2007
18928
12602,7
2008
23695
14940,6
2009
25151
16856,9
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) - 49694.9535
После линеаризации получим: ln(y) = ln(a) + x ln(b)
Эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
y = e 7.8132 *e 0.000162x = 2473.06858*1.00016 xx
y
1/x
ln(x)
ln(y)
515.9
872
0.00194
6.25
6.77
2281.1
3813
0.000438
7.73
8.25
3062
5014
0.000327
8.03
8.52
3947.2
6400
0.000253
8.28
8.76
5170.4
7708
0.000193
8.55
8.95
6410.3
9848
0.000156
8.77
9.2
8111.9
12455
0.000123
9
9.43
10196
15284
9.8E-5
9.23
9.63
12602.7
18928
7.9E-5
9.44
9.85
14940.6
23695
6.7E-5
9.61
10.07
16856.9
25151
5.9E-5
9.73
10.13
4. Временные ряды.
4.1. Характеристики временных рядов. Выявление тренда в динамических рядах экономических показателей.




