Множественный коэффициент корреляции и множественный коэффициент детерминации. Множественная линейная корреляция
Множественный коэффициент корреляции характеризует тесноту линейной связи между одной переменной и совокупностью других рассматриваемых переменных.Особое значение имеет расчет множественного коэффициента корреляции результативного признака y с факторными x 1 , x 2 ,…, x m , формула для определения которого в общем случае имеет вид
где ∆ r – определитель корреляционной матрицы; ∆ 11 – алгебраическое дополнение элемента r yy корреляционной матрицы.
Если рассматриваются лишь два факторных признака, то для вычисления множественного коэффициента корреляции можно использовать следующую формулу:

Построение множественного коэффициента корреляции целесообразно только в том случае, когда частные коэффициенты корреляции оказались значимыми, и связь между результативным признаком и факторами, включенными в модель, действительно существует.
Коэффициент детерминации
Общая формула: R 2 = RSS/TSS=1-ESS/TSSгде RSS - объясненная сумма квадратов отклонений, ESS - необъясненная (остаточная) сумма квадратов отклонений, TSS - общая сумма квадратов отклонений (TSS=RSS+ESS)
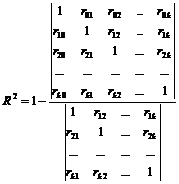 ,
,
где r ij - парные коэффициенты корреляции между регрессорами x i и x j , a r i 0 - парные коэффициенты корреляции между регрессором x i и y ;
- скорректированный (нормированный) коэффициент детерминации.
Квадрат множественного коэффициента корреляции ![]() называется множественным коэффициентом детерминации
; он показывает, какая доля дисперсии результативного признака y
объясняется влиянием факторных признаков x 1 , x 2 , …,x m . Заметим, что формула для вычисления коэффициента детерминации через соотношение остаточной и общей дисперсии результативного признака даст тот же результат.
называется множественным коэффициентом детерминации
; он показывает, какая доля дисперсии результативного признака y
объясняется влиянием факторных признаков x 1 , x 2 , …,x m . Заметим, что формула для вычисления коэффициента детерминации через соотношение остаточной и общей дисперсии результативного признака даст тот же результат.
Множественный коэффициент корреляции и коэффициент детерминации изменяются в пределах от 0 до 1. Чем ближе к 1, тем связь сильнее и, соответственно, тем точнее уравнение регрессии, построенное в дальнейшем, будет описывать зависимость y
от x 1 , x 2 , …,x m . Если значение множественного коэффициента корреляции невелико (меньше 0,3), это означает, что выбранный набор факторных признаков в недостаточной мере описывает вариацию результативного признака либо связь между факторными и результативной переменными является нелинейной.
Рассчитывается множественный коэффициент корреляции с помощью калькулятора . Значимость множественного коэффициента корреляции и коэффициента детерминации проверяется с помощью критерия Фишера .
Какое из приведенных чисел может быть значением коэффициента множественной детерминации:
а) 0,4 ;
б) -1;
в) -2,7;
г) 2,7.
Множественный линейный коэффициент корреляции равен 0.75 . Какой процент вариации зависимой переменной у учтен в модели и обусловлен влиянием факторов х 1 и х 2 .
а) 56,2 (R 2 =0.75 2 =0.5625);
Множественный коэффициент корреляции используется в качестве меры степени тесноты статистической связи между результирующим показателем (зависимой переменной) y и набором объясняющих (независимых) переменных или, иначе говоря, оценивает тесноту совместного влияния факторов на результат.
Множественный коэффициент корреляции может быть вычислен по ряду формул 5 , в том числе:
с использованием матрицы парных коэффициентов корреляции
 ,
(3.18)
,
(3.18)
где
r
- определитель матрицы парных коэффициентов
корреляции y
, ,
,
r
11
- определитель матрицы межфакторной
корреляции
 ;
;

 .
(3.19)
.
(3.19)
Для модели, в которой присутствуют две независимые переменные, формула (3.18) упрощается
 .
(3.20)
.
(3.20)
Квадрат множественного коэффициента корреляции равен коэффициенту детерминации R 2 . Как и в случае парной регрессии, R 2 свидетельствует о качестве регрессионной модели и отражает долю общей вариации результирующего признака y , объясненную изменением функции регрессии f (x ) (см. 2.4). Кроме того, коэффициент детерминации может быть найден по формуле
 .
(3.21)
.
(3.21)
Однако использование R 2 в случае множественной регрессии является не вполне корректным, так как коэффициент детерминации возрастает при добавлении регрессоров в модель. Это происходит потому, что остаточная дисперсия уменьшается при введении дополнительных переменных. И если число факторов приблизится к числу наблюдений, то остаточная дисперсия будет равна нулю, и коэффициент множественной корреляции, а значит и коэффициент детерминации, приблизятся к единице, хотя в действительности связь между факторами и результатом и объясняющая способность уравнения регрессии могут быть значительно ниже.
Для того чтобы получить адекватную оценку того, насколько хорошо вариация результирующего признака объясняется вариацией нескольких факторных признаков, применяют скорректированный коэффициент детерминации
 (3.22)
(3.22)
Скорректированный
коэффициент детерминации всегда меньше
R
2 .
Кроме того, в отличие от R
2 ,
который всегда положителен,
 может принимать и отрицательное значение.
может принимать и отрицательное значение.
Пример (продолжение примера 1) . Рассчитаем множественный коэффициент корреляции, согласно формуле (3.20):
Величина множественного коэффициента корреляции, равного 0,8601, свидетельствует о сильной взаимосвязи стоимости перевозки с весом груза и расстоянием, на которое он перевозится.
Коэффициент детерминации равен: R 2 =0,7399.
Скорректированный коэффициент детерминации рассчитываем по формуле (3.22):
 =0,7092.
=0,7092.
Заметим, что величина скорректированного коэффициента детерминации отличается от величины коэффициента детерминации.
Таким образом, 70,9% вариации зависимой переменной (стоимости перевозки) объясняется вариацией независимых переменных (весом груза и расстоянием перевозки). Остальные 29,1% вариации зависимой переменной объясняются факторами, неучтенными в модели.
Величина скорректированного коэффициента детерминации достаточно велика, следовательно, мы смогли учесть в модели наиболее существенные факторы, определяющие стоимость перевозки.
Сегодня уже все, кто хоть немного интересуется дата майнингом, наверняка слышали про простую линейную регрессию . Про нее уже писали на хабре, а также подробно рассказывал Эндрю Нг в своем известном курсе машинного обучения. Линейная регрессия является одним из базовых и самых простых методов машинного обучения, однако очень редко упоминаются методы оценки качества построенной модели. В этой статье я постараюсь немного исправить это досадное упущение на примере разбора результатов функции summary.lm() в языке R. При этом я постараюсь предоставить необходимые формулы, таким образом все вычисления можно легко запрограммировать на любом другом языке. Эта статья предназначена для тех, кто слышал о том, что можно строить линейную регрессию, но не сталкивался со статистическими процедурами для оценки ее качества.Модель линейной регрессии
Итак, пусть есть несколько независимых случайных величин X1, X2, ..., Xn (предикторов) и зависящая от них величина Y (предполагается, что все необходимые преобразования предикторов уже сделаны). Более того, мы предполагаем, что зависимость линейная, а ошибки рапределены нормально, то естьГде I - единичная квадратная матрица размера n x n.
Итак, у нас есть данные, состоящие из k наблюдений величин Y и Xi и мы хотим оценить коэффициенты. Стандартным методом для нахождения оценок коэффициентов является метод наименьших квадратов . И аналитическое решение, которое можно получить, применив этот метод, выглядит так:
где b
с крышкой - оценка вектора коэффициентов, y
- вектор значений зависимой величины, а X - матрица размера k x n+1 (n - количество предикторов, k - количество наблюдений), у которой первый столбец состоит из единиц, второй - значения первого предиктора, третий - второго и так далее, а строки соответствуют имеющимся наблюдениям.
Функция summary.lm() и оценка получившихся результатов
Теперь рассмотрим пример построения модели линейной регрессии в языке R:> library(faraway) > lm1<-lm(Species~Area+Elevation+Nearest+Scruz+Adjacent, data=gala) > summary(lm1) Call: lm(formula = Species ~ Area + Elevation + Nearest + Scruz + Adjacent, data = gala) Residuals: Min 1Q Median 3Q Max -111.679 -34.898 -7.862 33.460 182.584 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.068221 19.154198 0.369 0.715351 Area -0.023938 0.022422 -1.068 0.296318 Elevation 0.319465 0.053663 5.953 3.82e-06 *** Nearest 0.009144 1.054136 0.009 0.993151 Scruz -0.240524 0.215402 -1.117 0.275208 Adjacent -0.074805 0.017700 -4.226 0.000297 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 60.98 on 24 degrees of freedom Multiple R-squared: 0.7658, Adjusted R-squared: 0.7171 F-statistic: 15.7 on 5 and 24 DF, p-value: 6.838e-07
Таблица gala содержит некоторые данные о 30 Галапагосских островах. Мы будем рассматривать модель, где Species - количество разных видов растений на острове линейно зависит от нескольких других переменных.
Рассмотрим вывод функции summary.lm().
Сначала идет строка, которая напоминает, как строилась модель.
Затем идет информация о распределении остатков: минимум, первая квартиль, медиана, третья квартиль, максимум. В этом месте было бы полезно не только посмотреть на некоторые квантили остатков, но и проверить их на нормальность, например тестом Шапиро-Уилка.
Далее - самое интересное - информация о коэффициентах. Здесь потребуется немного теории.
Сначала выпишем следующий результат:
при этом сигма в квадрате с крышкой является несмещенной оценкой для реальной сигмы в квадрате. Здесь b
- реальный вектор коэффициентов, а эпсилон с крышкой - вектор остатков, если в качестве коэффициентов взять оценки, полученные методом наименьших квадратов. То есть при предположении, что ошибки распределены нормально, вектор коэффициентов тоже будет распределен нормально вокруг реального значения, а его дисперсию можно несмещенно оценить. Это значит, что можно проверять гипотезу на равенство коэффициентов нулю, а следовательно проверять значимость предикторов, то есть действительно ли величина Xi сильно влияет на качество построенной модели.
Для проверки этой гипотезы нам понадобится следующая статистика, имеющая распределение Стьюдента в том случае, если реальное значение коэффициента bi равно 0:
где![]() - стандартная ошибка оценки коэффициента, а t(k-n-1) - распределение Стьюдента с k-n-1 степенями свободы.
- стандартная ошибка оценки коэффициента, а t(k-n-1) - распределение Стьюдента с k-n-1 степенями свободы.
Теперь все готово для продолжения разбора вывода функции summary.lm().
Итак, далее идут оценки коэффициентов, полученные методом наименьших квадратов, их стандартные ошибки, значения t-статистики и p-значения для нее. Обычно p-значение сравнивается с каким-нибудь достаточно малым заранее выбранным порогом, например 0.05 или 0.01. И если значение p-статистики оказывается меньше порога, то гипотеза отвергается, если же больше, ничего конкретного, к сожалению, сказать нельзя. Напомню, что в данном случае, так как распределение Стьюдента симметричное относительно 0, то p-значение будет равно 1-F(|t|)+F(-|t|), где F - функция распределения Стьюдента с k-n-1 степенями свободы. Также, R любезно обозначает звездочками значимые коэффициенты, для которых p-значение достаточно мало. То есть, те коэффициенты, которые с очень малой вероятностью равны 0. В строке Signif. codes как раз содержится расшифровка звездочек: если их три, то p-значение от 0 до 0.001, если две, то оно от 0.001 до 0.01 и так далее. Если никаких значков нет, то р-значение больше 0.1.
В нашем примере можно с большой уверенностью сказать, что предикторы Elevation и Adjacent действительно с большой вероятностью влияют на величину Species, а вот про остальные предикторы ничего определенного сказать нельзя. Обычно, в таких случаях предикторы убирают по одному и смотрят, насколько изменяются другие показатели модели, например BIC или Adjusted R-squared, который будет разобран далее.
Значение Residual standart error соответствует просто оценке сигмы с крышкой, а степени свободы вычисляются как k-n-1.
А теперь самая важные статистики, на которые в первую очередь стоит смотреть: R-squared и Adjusted R-squared:
где Yi - реальные значения Y в каждом наблюдении, Yi с крышкой - значения, предсказанные моделью, Y с чертой - среднее по всем реальным значениям Yi.![]()
Начнем со статистики R-квадрат или, как ее иногда называют, коэффициента детерминации. Она показывает, насколько условная дисперсия модели отличается от дисперсии реальных значений Y. Если этот коэффициент близок к 1, то условная дисперсия модели достаточно мала и весьма вероятно, что модель неплохо описывает данные. Если же коэффициент R-квадрат сильно меньше, например, меньше 0.5, то, с большой долей уверенности модель не отражает реальное положение вещей.
Однако, у статистики R-квадрат есть один серьезный недостаток: при увеличении числа предикторов эта статистика может только возрастать. Поэтому, может показаться, что модель с большим количеством предикторов лучше, чем модель с меньшим, даже если все новые предикторы никак не влияют на зависимую переменную. Тут можно вспомнить про принцип бритвы Оккама . Следуя ему, по возможности, стоит избавляться от лишних предикторов в модели, поскольку она становится более простой и понятной. Для этих целей была придумана статистика скорректированный R-квадрат. Она представляет собой обычный R-квадрат, но со штрафом за большое количество предикторов. Основная идея: если новые независимые переменные дают большой вклад в качество модели, значение этой статистики растет, если нет - то наоборот уменьшается.
Для примера рассмотрим ту же модель, что и раньше, но теперь вместо пяти предикторов оставим два:
> lm2<-lm(Species~Elevation+Adjacent, data=gala)
> summary(lm2)
Call:
lm(formula = Species ~ Elevation + Adjacent, data = gala)
Residuals:
Min 1Q Median 3Q Max
-103.41 -34.33 -11.43 22.57 203.65
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.43287 15.02469 0.095 0.924727
Elevation 0.27657 0.03176 8.707 2.53e-09 ***
Adjacent -0.06889 0.01549 -4.447 0.000134 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 60.86 on 27 degrees of freedom
Multiple R-squared: 0.7376, Adjusted R-squared: 0.7181
F-statistic: 37.94 on 2 and 27 DF, p-value: 1.434e-08
Как можно увидеть, значение статистики R-квадрат снизилось, однако значение скорректированного R-квадрат даже немного возросло.
Теперь проверим гипотезу о равенстве нулю всех коэффициентов при предикторах. То есть, гипотезу о том, зависит ли вообще величина Y от величин Xi линейно. Для этого можно использовать следующую статистику, которая, если гипотеза о равенстве нулю всех коэффициентов верна, имеет
Множественный коэффициент корреляции трех переменных – это показатель тесноты линейной связи между одним из признаков (буква индекса перед тире) и совокупностью двух других признаков (буквы индекса после тире):
 ; (12.7)
; (12.7)
 (12.8)
(12.8)
Эти формулы позволяют легко вычислить множественные коэффициенты корреляции при известных значениях коэффициентов парной корреляции r xy , r xz и r yz .
Коэффициент R не отрицателен и всегда находится в пределах от 0 до 1. При приближении R к единице степень линейной связи трех признаков увеличивается. Между коэффициентом множественной корреляции, например R y-xz , и двумя коэффициентами парной корреляции r yx и r yz существует следующее соотношение: каждый из парных коэффициентов не может превышать по абсолютной величине R y-xz .
Квадрат коэффициента множественной корреляции R 2 называется коэффициентом множественной детерминации. Он показывает долю вариации зависимой переменной под воздействием изучаемых факторов.
Значимость множественной корреляции оценивается по
F
–критерию:
 , (12.9)
, (12.9)
n – объем выборки,
k – число признаков; в нашем случае k = 3.
Теоретическое значение F –критерия берут из таблицы приложений для ν 1 = k –1 и ν 2 = n–k степеней свободы и принятого уровня значимости. Нулевая гипотеза о равенстве множественного коэффициента корреляции в совокупности нулю (H 0:R = 0) принимается, если F факт. < F табл . и отвергается, если F факт. ≥ F табл .
Конец работы -
Эта тема принадлежит разделу:
Математическая статистика
Учреждение образования.. гомельский государственный университет.. имени франциска скорины ю м жученко..
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ:
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Все темы данного раздела:
Учебное пособие
для студентов вузов, обучающихся по специальности 1-31 01 01 «Биология»
Гомель 2010
Предмет и метод математической статистики
Предмет математической статистики – изучение свойств массовых явлений в биологии, экономике, технике и других областях. Эти явления обычно представляются сложными, вследствие разнообразия (варьиров
Понятие случайного события
Статистическая индукция или статистические заключения, как главная составная часть метода исследования массовых явлений, имеют свои отличительные черты. Статистические заключения делают с численно
Вероятность случайного события
Числовая характеристика случайного события, обладающая тем свойством, что для любой достаточно большой серии испытаний частота события лишь незначительно отличается от этой характеристики, называет
Вычисление вероятностей
Часто возникает необходимость одновременно складывать и умножать вероятности. Например, требуется определить вероятность выпадения 5 очков при одновременном бросании 2 кубиков. Искомая сумма вероят
Понятие случайной переменной
Определив понятие вероятности и выяснив ее главные свойства, перейдем к рассмотрению одного из важнейших понятий теории вероятностей – понятия случайной переменной.
Допустим, что в результ
Дискретные случайные переменные
Случайная переменная дискретна, если совокупность возможных ее значений конечна, или, по крайней мере, поддается счислению. Предположим, что случайная переменная X может принимать значения x1
Непрерывные случайные переменные
В противоположность дискретным случайным переменным, рассмотренным в предыдущем подразделе, совокупность возможных значений непрерывной случайной переменной не только не конечна, но и не поддается
Математическое ожидание и дисперсия
Часто возникает необходимость охарактеризовать распределение случайной переменной с помощью одного–двух числовых показателей, выражающих наиболее существенные свойства этого распределения. К таким
Моменты
Большое значение в математической статистике имеют так называемые моменты распределения случайной переменной. В математическом ожидании большие значения случайной величины учитываются недостаточно.
Биномиальное распределение и измерение вероятностей
В этой теме рассмотрим основные типы распределения дискретных случайных переменных. Предположим, что вероятность наступления некоторого случайного события А при единичном испытании равно
Прямоугольное (равномерное) распределение
Прямоугольное (равномерное) распределение - простейший тип непрерывных распределений. Если случайная переменная X может принимать любое действительное значение в интервале (а, b), где а и b – дейст
Нормальное распределение
Нормальное распределение играет основную роль в математической статистике. Это ни в малейшей степени не является случайным: в объективной действительности весьма часто встречаются различные признак
Логарифмически нормальное распределение
Случайная переменная Y имеет логарифмически нормальное распределение с параметрами μ и σ, если случайная переменная X = lnY имеет нормальное распределение с теми же параметрами μ и &
Средние величины
Из всех групповых свойств наибольшее теоретическое и практическое значение имеет средний уровень, измеряемый средней величиной признака.
Средняя величина признака – понятие очень глубокое,
Общие свойства средних величин
Для правильного использования средних величин необходимо знать свойства этих показателей: срединное расположение, абстрактность и единство суммарного действия.
По своему численному значени
Средняя арифметическая
Средняя арифметическая, обладая общими свойствами средних величин, имеет свои особенности, которые можно выразить следующими формулами:
Средний ранг (непараметрическая средняя)
Средний ранг определяется для таких признаков, для которых еще не найдены способы количественного измерения. По степени проявления таких признаков объекты могут быть ранжированы, т. е. расположены
Взвешенная средняя арифметическая
Обычно, чтобы рассчитать среднюю арифметическую, складывают все значения признака и полученную сумму делят на число вариантов. В этом случае каждое значение, входя в сумму, увеличивает ее на полную
Средняя квадратическая
Средняя квадратическая вычисляется по формуле:
, (6.5)
Она равна корню квадратному из суммы
Медиана
Медианой называют такое значение признака, которое разделяет всю группу на две равные части: одна часть имеет значения признака меньшее, чем медиана, а другая – большее.
Например, если име
Средняя геометрическая
Чтобы получить среднюю геометрическую для группы с n данными, нужно все варианты перемножить и из полученного произведения извлечь корень n-й степени:
Средняя гармоническая
Средняя гармоническая рассчитывается по формуле. (6.14)
Для пяти вариантов: 1, 4, 5, 5 сре
Число степеней свободы
Число степеней свободы равно числу элементов свободного разнообразия в группе. Оно равно числу всех имеющихся элементов изучения без числа ограничений разнообразия.
Например, для исследова
Коэффициент вариации
Стандартное отклонение – величина именованная, выраженная в тех же единицах измерения, как и средняя арифметическая.
Поэтому для сравнения разных признаков, выраженных в разных единицах из
Лимиты и размах
Для быстрой и примерной оценки степени разнообразия часто применяются простейшие показатели:
lim = {min ¸ max} – лимиты, т. е. наименьшее и наибольшее значения признака,
p =
Нормированное отклонение
Обычно степень развития признака определяется путем его измерения и выражается определенным именованным числом: 3 кг веса, 15 см длины, 20 зацепок на крыле у пчел, 4% жира в молоке, 15 кг настрига
Средняя и сигма суммарной группы
Иногда бывает необходимо определить среднюю и сигму для суммарного распределения, составленного из нескольких распределений. При этом известны не сами распределения, а только их средние и сигмы.
Скошенность (асимметрия) и крутизна (эксцесс) кривой распределения
Для больших выборок (n > 100) вычисляют еще два статистических показателя.
Скошенность кривой называется асимметрией:
Вариационный ряд
По мере увеличения численности изучаемых групп все более и более проявляется та закономерность в разнообразии, которая в малочисленных группах была скрыта случайной формой своего проявления.
Гистограмма и вариационная кривая
Гистограмма – это вариационный ряд, представленный в виде диаграммы, в которой различная величина частот изображается различной высотой столбиков. Гистограмма распределения данных представлена на р
Достоверность различия распределений
Статистическая гипотеза – это определённое предположение о распределении вероятностей, лежащем в основе наблюдаемой выборки данных.
Проверка статистической гипотезы – это процесс принятия
Критерий по асимметрии и эксцессу
Некоторые признаки растений, животных и микроорганизмов при объединении объектов в группы дают распределения, значительно отличающиеся от нормального.
В тех случаях, когда какие-нибудь при
Генеральная совокупность и выборка
Весь массив особей определенной категории называется генеральной совокупностью. Объем генеральной совокупности определяется задачами исследования.
Если изучается какой-нибудь вид диких жив
Репрезентативность
Непосредственное изучение группы отобранных объектов дает, прежде всего, первичный материал и характеристику самой выборки.
Все выборочные данные и сводные показатели имеют значение в каче
Ошибки репрезентативности и другие ошибки исследований
Оценка генеральных параметров по выборочным показателям имеет свои особенности.
Часть никогда не может полностью охарактеризовать все целое, поэтому характеристика генеральной совокупности
Доверительные границы
Определять величину ошибок репрезентативности необходимо для того, чтобы выборочные показатели использовать еще и для нахождения возможных значений генеральных параметров. Этот процесс называется о
Общий порядок оценки
Три величины, необходимые для оценки генерального параметра, – выборочный показатель (), критерий надежности
Оценка средней арифметической
Оценка средней величины имеет целью установить величину генеральной средней для изученной категории объектов. Требуемая для этой цели ошибка репрезентативности определяется по формуле:
Оценка средней разности
В некоторых исследованиях в качестве первичных данных берется разность двух измерений. Это может быть в случае, когда каждая особь выборки изучается в двух состояниях – или в разном возрасте, или п
Недостоверная и достоверная оценка средней разности
Такие результаты выборочных исследований, по которым нельзя получить никакой определенной оценки генерального параметра (или он больше нуля, или меньше, или равен нулю), называются недостоверными.
Оценка разности генеральных средних
В биологических исследованиях особое значение имеет разность двух величин. По разности ведется сравнение разных популяций, рас, пород, сортов, линий, семейств, опытных и контрольных групп (метод гр
Критерий достоверности разности
При том большом значении, которое имеет для исследователей получение достоверных разностей, появляется необходимость овладеть методами, позволяющими определить – достоверна ли полученная, реально с
Репрезентативность при изучении качественных признаков
Качественные признаки обычно не могут иметь градаций проявления: они или имеются, или не имеются у каждой из особей, например пол, комолость, наличие или отсутствие каких-нибудь особенностей, уродс
Достоверность разности долей
Достоверность разности выборочных долей определяется так же, как и для разности средних:
(10.34)
Коэффициент корреляции
Во многих исследованиях требуется изучить несколько признаков в их взаимной связи. Если вести такое исследование по отношению к двум признакам, то можно заметить, что изменчивость одного признака н
Ошибка коэффициента корреляции
Как и всякая выборочная величина, коэффициент корреляции имеет свою ошибку репрезентативности, вычисляемую для больших выборок по формуле:
Достоверность выборочного коэффициента корреляции
Критерий выборочного коэффициента корреляции определяется по формуле:
(11.9)
где:
Доверительные границы коэффициента корреляции
Доверительные границы генерального значения коэффициента корреляции находятся общим способом по формуле:
Достоверность разности двух коэффициентов корреляции
Достоверность разности коэффициентов корреляции определяется так же, как и достоверность разности средних, по обычной формуле
Уравнение прямолинейной регрессии
Прямолинейная корреляция отличается тем, что при этой форме связи каждому из одинаковых изменений первого признака соответствует вполне определенное и тоже одинаковое в среднем изменение другого пр
Ошибки элементов уравнения прямолинейной регрессии
В уравнении простой прямолинейной регрессии:
у = а + bх
возникают три ошибки репрезентативности.
1 Ошибка коэффициента регрессии:
Частный коэффициент корреляции
Частный коэффициент корреляции – это показатель, измеряющий степень сопряженности двух признаков при постоянном значении третьего.
Математическая статистика позволяет установить корреляцию
Линейное уравнение множественной регрессии
Математическое уравнение для прямолинейной зависимости между тремя переменными называется множественным линейным уравнением плоскости регрессии. Оно имеет следующий общий вид:
Корреляционное отношение
Если связь между изучаемыми явлениями существенно отклоняется от линейной, что легко установить по графику, то коэффициент корреляции непригоден в качестве меры связи. Он может указать на отсутстви
Свойства корреляционного отношения
Корреляционное отношение измеряет степень корреляции при любой ее форме.
Кроме того, корреляционное отношение обладает рядом других свойств, представляющих большой интерес в статистическом
Ошибка репрезентативности корреляционного отношения
Еще не разработано точной формулы ошибки репрезентативности корреляционного отношения. Обычно приводимая в учебниках формула имеет недостатки, которыми не всегда можно пренебречь. Эта формула не уч
Критерий линейности корреляции
Для определения степени приближения криволинейной зависимости к прямолинейной используется критерий F, вычисляемый по формуле:
Дисперсионный комплекс
Дисперсионный комплекс – это совокупность градаций с привлеченными для исследования данными и средними из данных по каждой градации (частные средние) и по всему комплексу (общая средняя).
Статистические влияния
Статистическое влияние – это отражение в разнообразии результативного признака того разнообразия фактора (его градаций), которое организовано в исследовании.
Для оценки влияния фактора нео
Факториальное влияние
Факториальное влияние – это простое или комбинированное статистическое влияние изучаемых факторов.
В однофакторных комплексах изучается простое влияние одного фактора при определенных орга
Однофакторный дисперсионный комплекс
Дисперсионный анализ разработан и введен в практику сельскохозяйственных и биологических исследований английским ученым Р. А. Фишером, который открыл закон распределения отношения средних квадратов
Многофакторный дисперсионный комплекс
Ясное представление о математической модели дисперсионного анализа облегчает понимание необходимых вычислительных операций, особенно при обработке данных многофакторных опытов, в которых больше ист
Преобразования
Правильное использование дисперсионного анализа для обработки экспериментального материала предполагает однородность дисперсий по вариантам (выборкам), нормальное или близкое к нему распределение в
Показатели силы влияний
Определение силы влияний по их результатам требуется в биологии, сельском хозяйстве, медицине для выбора наиболее эффективных средств воздействия, для дозировки физических и химических агентов – ст
Ошибка репрезентативности основного показателя силы влияния
Точная формула ошибки основного показателя силы влияния еще не найдена.
В однофакторных комплексах, когда ошибка репрезентативности определяется только для одного показателя факториального
Предельные значения показателей силы влияния
Основной показатель силы влияния равен доле одного слагаемого от всей суммы слагаемых. Кроме того, этот показатель равен квадрату корреляционного отношения. По этим двум причинам показатель силы вл
Достоверность влияний
Основной показатель силы влияния, полученный в выборочном исследовании, характеризует, прежде всего, ту степень влияния, которая реально, в действительности, проявилась в группе исследованных объек
Дискриминантный анализ
Дискриминантный анализ является одним из методов многомерного статистического анализа. Цель дискриминантного анализа состоит в том, чтобы на основе измерения различных характеристик (признаков, пар
Постановка задачи, методы решения, ограничения
Предположим, имеется n объектов с m характеристиками. В результате измерений каждый объект характеризуется вектором x1 ... xm, m >1. Задача состоит в том, что
Предположения и ограничения
Дискриминантный анализ «работает» при выполнении ряда предположений.
Предположение о том, что наблюдаемые величины – измеряемые характеристики объекта – имеют нормальное распределение. Это
Алгоритм дискриминантного анализа
Решение задач дискриминации (дискриминантный анализ) состоит в разбиении всего выборочного пространства (множества реализации всех рассматриваемых многомерных случайных величин) на некоторое число
Кластерный анализ
Кластерный анализ объединяет различные процедуры, используемые для проведения классификации. В результате применения этих процедур исходная совокупность объектов разделяется на кластеры или группы
Методы кластерного анализа
В практике обычно реализуются агломеративные методы кластеризации.
Обычно перед началом классификации данные стандартизуются (вычитается среднее и производится деление на корень квадратный
Алгоритм кластерного анализа
Кластерный анализ – это совокупность методов классификации многомерных наблюдений или объектов, основанных на определении понятия расстояния между объектами с последующим выделением из них групп, &
Коэффициент обладает следующими свойствами:
1) не имеет размерности, следовательно, сопоставим для величин различных порядков;
2) изменяется в диапазоне от –1 до +1. Положительное значение свидетельствует о прямой линейной связи, отрицательное – об обратной. Чем ближе абсолютное значение коэффициента к единице, тем теснее связь. Считается, что связь достаточно сильная, если коэффициент по абсолютной величине превышает 0,7, и слабая, если он менее 0,3.
Значение коэффициента легко вычисляется при помощи MS Excel (функция КОРРЕЛ).
Величина r 2 называется коэффициентом детерминации . Он определяет долю вариации одной из переменных, которая объясняется вариацией другой переменной.
6. Коэффициент множественной корреляции
Экономические явления чаще всего адекватно описываются именно многофакторными моделями. Поэтому возникает необходимость обобщить рассмотренное выше корреляционное отношение (6.4) на случай нескольких переменных.
Теснота линейной взаимосвязи между переменной y и рядом переменных x j , рассматриваемых в целом, может быть определена с помощью коэффициента множественной корреляции .
Предположим, что переменная y испытывает влияние двух переменных - x и z . В этом случае коэффициент множественной корреляции может быть определен по формуле:
| . | (6.9) |
где r yx , r yz , r xz - простые коэффициенты линейной парной корреляции, определенные из соотношения (6.4).
Коэффициент множественной корреляции заключен в пределах 0 ≤ R ≤ 1. Он не меньше, чем абсолютная величина любого парного или частного коэффициента корреляции с таким же первичным индексом.
С помощью множественного коэффициента (по мере приближения R к 1) делается вывод о тесноте взаимосвязи, но не о ее направлении. Величина R 2 , называемая множественным коэффициентом детерминации , показывает, какую долю вариации исследуемой переменной (y ) объясняет вариация остальных учтенных переменных (x , z ).
7. Коэффициент частной корреляции
Иногда представляет интерес измерение частных зависимостей (между y и x j ) при условии, что воздействие других факторов, принимаемых во внимание, устранено. В качестве соответствующих измерителей приняты коэффициенты частной корреляции .
Рассмотрим порядок расчета коэффициента частной корреляции для случая, когда во взаимосвязи находятся три случайные переменные – x , y , z . Для них могут быть получены простые коэффициенты линейной парной корреляции – r yx , r yz , r xz . Однако большая величина этого коэффициента может быть обусловлена не только тем, что y и x действительно связаны между собой, но и в силу того, что обе переменные испытывают сильное действие третьего фактора – z .
Коэффициент частной корреляции отличается от простого коэффициента линейной парной корреляции тем, что он измеряет парную корреляцию соответствующих признаков (y и x ) при условии, что влияние на них третьего фактора (z ) устранено.
Соответствующая расчетная формула:
|
|
(6.10) |
Частный коэффициент корреляции, так же как и парный коэффициент корреляции r (рассчитанный по формуле (6.4)), может принимать значения от -1 до 1.




