Линейный тренд выражается следующей формулой. Методы определения параметров уравнения тренда
Наиболее часто тренд представляется линейной зависимостью исследуемой величины вида
где y – исследуемая переменная (например, производительность) или зависимая переменная;
x – число, определяющее позицию (второй, третий и т.д.) года в периоде прогнозирования или независимая переменная.
При линейной аппроксимации связи между двумя параметрами для нахождения эмпирических коэффициентов линейной функции используется наиболее часто метод наименьших квадратов. Суть метода состоит в том, что линейная функция «наилучшего соответствия» проходит через точки графика, соответствующие минимуму суммы квадратов отклонений измеряемого параметра. Такое условие имеет вид:

где n – объем исследуемой совокупности (число единиц наблюдений).

Рис. 5.3. Построение тренда методом наименьших квадратов
Значения констант b и a или коэффициента при переменной Х и свободного члена уравнения определяются по формуле:

В табл. 5.1 приведен пример вычисления линейного тренда по данным .
Таблица 5.1. Вычисление линейного тренда

Методы сглаживания колебаний.
При сильных расхождениях между соседними значениями тренд, полученный методом регрессии, трудно поддается анализу. При прогнозировании, когда ряд содержит данные с большим разбросом колебаний соседних значений, следует их сгладить по определенным правилам, а потом искать смысл в прогнозе. К методу сглаживания колебаний
относят: метод скользящих средних (рассчитывается n-точечное среднее), метод экспоненциального сглаживания. Рассмотрим их.
Метод «скользящих средних» (МСС).
МСС позволяет сгладить ряд значений с тем, чтобы выделить тренд. При использовании этого метода берется среднее (обычно среднеарифметическое) фиксированного числа значений. Например, трехточечное скользящее среднее. Берется первая тройка значений, составленная из данных за январь, февраль и март (10 + 12 + 13), и определяется среднее, равное 35: 3 = 11,67.
Полученное значение 11,67 ставится в центре диапазона, т.е. по строке февраля. Затем «скользим на один месяц» и берется вторая тройка чисел, начиная с февраля по апрель (12 + 13 + 16), и рассчитывается среднее, равное 41: 3 = 13,67, и таким приемом обрабатываем данные по всему ряду. Полученные средние представляют новый ряд данных для построения тренда и его аппроксимации. Чем больше берется точек для вычисления скользящей средней, тем сильнее происходит сглаживание колебаний. Пример из МВА построения тренда дан в табл. 5.2 и на рис. 5.4.
Таблица 5.2 Расчет тренда методом трехточечного скользящего среднего

Характер колебаний исходных данных и данных, полученных методом скользящего среднего, иллюстрирован на рис. 5.4. Из сравнения графиков рядов исходных значений (ряд 3) и трехточечных скользящих средних (ряд 4), видно, что колебания удается сгладить. Чем большее число точек будет вовлекаться в диапазон вычисления скользящей средней, тем нагляднее будет вырисовываться тренд (ряд 1). Но процедура укрупнения диапазона приводит к сокращению числа конечных значений и это снижает точность прогноза.
Прогнозы следует делать исходя из оценок линии регрессии, составленной по значениям исходных данных или скользящих средних.

Рис. 5.4. Характер изменения объема продаж по месяцам года:
исходные данные (ряд 3); скользящие средние (ряд 4); экспоненциальное сглаживание (ряд 2); тренд, построенный методом регрессии (ряд 1)
Метод экспоненциального сглаживания.
Альтернативный подход к сокращению разброса значений ряда состоит в использовании метода экспоненциального сглаживания. Метод получил название «экспоненциальное сглаживание» в связи с тем, что каждое значение периодов, уходящих в прошлое, уменьшается на множитель (1 – α).
Каждое сглаженное значение рассчитывается по формуле вида:
St =aYt +(1−α)St−1,
где St – текущее сглаженное значение;
Yt – текущее значение временного ряда; St – 1 – предыдущее сглаженное значение; α – сглаживающая константа, 0 ≤ α ≤ 1.
Чем меньше значение константы α , тем менее оно чувствительно к изменениям тренда в данном временном ряду.
Кривые роста, описывающие закономерности развития явлений во времени – это результат аналитического выравнивания динамических рядов. Выравнивание ряда с помощью тех или иных функций в большинстве случаев оказывается удобным средством описания эмпирических данных. Это средство при соблюдении ряда условий можно применить и для прогнозирования. Процесс выравнивания состоит из следующих основных этапов:
Выбора типа кривой, форма которой соответствует характеру изменения динамического ряда;
Определения численных значений (оценка) параметров кривой;
Апостериорного контроля качества выбранного тренда.
В современных ППП все перечисленные этапы реализуются одновременно, как правило, в рамках одной процедуры.
Аналитическое сглаживание с использованием той или иной функции позволяет получить выровненные, или, как их иногда не вполне правомерно называют, теоретические значения уровней динамического ряда, т. е. уровни, которые наблюдались бы, если бы динамика явления полностью совпадала с кривой. Эта же функция с некоторой корректировкой или без нее, применяется в качестве модели для экстраполяции (прогноза).
Вопрос о выборе типа кривой является основным при выравнивании ряда. При всех прочих равных условиях ошибка в решении этого вопроса оказывается более значимой по своим последствиям (особенно для прогнозирования), чем ошибка, связанная со статистическим оцениванием параметров.
Поскольку форма тренда объективно существует, то при выявлении ее следует исходить из материальной природы изучаемого явления, исследуя внутренние причины его развития, а также внешние условия и факторы на него влияющие. Только после глубокого содержательного анализа можно переходить к использованию специальных приемов, разработанных статистикой.
Весьма распространенным приемом выявления формы тренда является графическое изображение временного ряда. Но при этом велико влияние субъективного фактора, даже при отображении выровненных уровней.
Наиболее надежные методы выбора уравнения тренда основаны на свойствах различных кривых, применяемых при аналитическом выравнивании. Такой подход позволяет увязать тип тренда с теми или иными качественными свойствами развития явления. Нам представляется, что в большинстве случаев практически приемлемым является метод, который основывается на сравнении характеристик изменения приростов исследуемого динамического ряда с соответствующими характеристиками кривых роста. Для выравнивания выбирается та кривая, закон изменения прироста которой наиболее близок к закономерности изменения фактических данных.
При выборе формы кривой надо иметь в виду еще одно обстоятельство. Рост сложности кривой в целом ряде случаев может действительно увеличить точность описания тренда в прошлом, однако в связи с тем, что более сложные кривые содержат большее число параметров и более высокие степени независимой переменной, их доверительные интервалы будут, в общем, существенно шире, чем у более простых кривых при одном и том же периоде упреждения.
В настоящее время, когда использование специальных программ без особых усилий позволяет одновременно строить несколько видов уравнений, широко эксплуатируются формальные статистические критерии для определения лучшего уравнения тренда.
Из сказанного выше, по-видимому, можно сделать вывод о том, что выбор формы кривой для выравнивания представляет собой задачу, которая не решается однозначно, а сводится к получению ряда альтернатив. Окончательный выбор не может лежать в области формального анализа, тем более, если предполагается с помощью выравнивания не только статистически описать закономерность поведения уровня в прошлом, но и экстраполировать найденную закономерность в будущее. Вместе с тем различные статистические приемы обработки данных наблюдения могут принести существенную пользу, по крайней мере, с их помощью можно отвергнуть заведомо непригодные варианты и тем самым существенно ограничить поле выбора.
Рассмотрим наиболее используемые типы уравнений тренда:
1. Линейная форма тренда:
где – уровень ряда, полученный в результате выравнивания по прямой; – начальный уровень тренда; – средний абсолютный прирост, константа тренда.
Для линейной формы тренда характерно равенство так называемых первых разностей (абсолютных приростов) и нулевые вторые разности, т. е. ускорения.
2. Параболическая (полином 2-ой степени) форма тренда:
 (3.6)
(3.6)
Для данного типа кривой постоянными являются вторые разности (ускорение), а нулевыми – третьи разности.
Параболическая форма тренда соответствует ускоренному или замедленному изменению уровней ряда с постоянным ускорением. Если < 0 и > 0, то квадратическая парабола имеет максимум, если > 0 и < 0 – минимум. Для отыскания экстремума первую производную параболы по t приравнивают 0 и решают уравнение относительно t .
3. Логарифмическая форма тренда:
 , (3.7)
, (3.7)
где – константа тренда.
Логарифмическим трендом может быть описана тенденция, проявляющаяся в замедлении роста уровней ряда динамики при отсутствии предельно возможного значения. При достаточно большом t логарифмическая кривая становится мало отличимой от прямой линии.
4. Мультипликативная (степенная) форма тренда:
 (3.8)
(3.8)
5. Полином 3-ей степени:
Естественно, кривых, описывающих основные тенденции, гораздо больше. Однако формат учебного пособия не позволяет описать все их многообразие. Показанные далее приемы построения моделей позволят пользователю самостоятельно использовать другие функции, в частности обратные.
Для решения поставленной задачи по аналитическому сглаживанию динамических рядов в системе STATISTICA нам потребуется создать дополнительную переменную на листе с исходными данными переменной «ВГ2001-2010», который следует сделать активным.
Нам предстоит построить уравнение тренда, которое по существу является уравнением регрессии, в котором в качестве фактора выступает «время». Создаем переменную «Т», содержащую интервалы времени, 10 годам (с 2001 по 2010). Переменная «Т» будет состоять из натуральных чисел от 1 до 10, соответствующих указанным годам.
В итоге получается следующий рабочий лист (рис. 3.6)

Рис. 3.6. Рабочий лист с созданной переменной времени
Далее рассмотрим процедуру, позволяющую строить регрессионные модели как линейного, так и нелинейного типа. Для этого выбираем: Statistics/Advanced Linear/Nonlinear Models/Nonlinear Estimation (рис. 3.7). В появившемся окне (рис. 3.8) выбираем функцию User-specified Regression, Least Squares (построение моделей регрессии пользователем вручную, параметры уравнения находятся по методу наименьших квадратов (МНК)).
В следующем диалоговом окне (рис. 3.9) нажимаем на кнопку Function to be estimated , чтобы попасть на экран для задания модели вручную (рис. 3.10).

Рис. 3.7. Запуск процедуры Statistics/Advanced Linear/
Nonlinear Models/Nonlinear Estimation

Рис. 3.8. Окно процедуры Nonlinear Estimation

Рис. 3.9ю Окно процедуры User-Specified Regression, Least Squares

Рис. 3.10. Окно для реализации процедуры
задания уравнения тренда вручную
В верхней части экрана находится поле для ввода функции, в нижней части располагаются примеры ввода функций для различных ситуаций.
Прежде чем сформировать интересующие нас модели, необходимо пояснить некоторые условные обозначения. Переменные уравнений задаются в формате «v №», где «v » обозначает переменную (от англ. «variable »), а «№» – номер столбца, в котором она расположена в таблице на рабочем листе с исходными данными. Если переменных очень много, то справа находится кнопка Review vars , позволяющая выбирать их из списка по названиям и просматривать их параметры с помощью кнопки Zoom (рис. 3.11).

Рис. 3.11. Окно выбора переменной с помощью кнопки Review vars
Параметры уравнений обозначаются любыми латинскими буквами, не обозначающими какое-либо математическое действие. Для упрощения работы предлагается обозначать параметры уравнения так, как в описании уравнений тренда – латинской буквой «а », последовательно присваивая им порядковые номера. Знаки математических действий (вычитания, сложения, умножения и пр.) задаются в обычном для Windows -приложений формате. Пробелы между элементами уравнения не требуются.
Итак, рассмотрим первую модель тренда – линейную, .
Следовательно, после набора она будет выглядеть следующим образом:
![]() ,
,
где v 1 – это столбец на листе с исходными данными, в котором находятся значения исходного динамического ряда; а 0 и а 1 – параметры уравнения; v 2 – столбец на листе с исходными данными, в котором находятся значения интервалов времени (переменная Т) (рис. 3.12).
После этого дважды нажимаем кнопку ОК .

Рис. 3.12. Окно процедуры задания уравнения линейного тренда

Рис. 3.13. Закладка Quick процедуры оценки уравнения тренда.
В появившемся окне (рис. 3.13) можно выбрать метод оценки параметров уравнения регрессии (Estimation method ), если это необходимо. В нашем случае нужно перейти к закладке Advanced и нажать на кнопку Start values (рис. 3.14). В этом диалоге задаются стартовые значения параметров уравнения для их нахождения по МНК, т.е. их минимальные значения. Изначально они заданы как 0,1 для всех параметров. В нашем случае можно оставить эти значения в том же виде, но если значения в наших исходных данных меньше единицы, то необходимо задать их в виде 0,001 для всех параметров уравнения тренда (рис. 3.15). Далее нажимаем кнопку ОК .

Рис. 3.14. Закладка Advanced процедуры оценки уравнения тренда

Рис. 3.15. Окно задания стартовыхзначений параметров уравнения тренда

Рис. 3.16. Закладка Quick окна результатов регрессионного анализа
На закладке Quick (рис.3.16) очень важным является значение строчки Proportion of variance accounted for , которое соответствует коэффициенту детерминации; это значение лучше записать отдельно, так как в дальнейшем оно выводиться не будет, и пользователю придется рассчитывать коэффициент вручную, при этом достаточно трех знаков после запятой. Далее нажимаем кнопку Summary: Parameter estimates для получения данных о параметрах линейного уравнения тренда (рис. 3.17).

Рис. 3.17. Результаты расчета параметров линейной модели тренда
Столбец Estimate – числовые значения параметров уравнения; Standard еrror – стандартная ошибка параметра; t-value – расчетное значение t -критерия; df – число степеней свободы (n -2); p-level – расчетный уровень значимости; Lo. Conf. Limit и Up. Conf. Limit – соответственно нижняя и верхняя граница доверительных интервалов для параметров уравнения с установленной вероятностью (указана как Level of Confidence в верхнем поле таблицы).
Соответственно уравнение линейно модели тренда имеет вид .
После этого возвращаемся к анализу и нажимаем на кнопку Analysis of Variance (дисперсионный анализ) на той же закладке Quick (см. рис. 3.16).

Рис. 3.18. Результаты дисперсионного анализа линейной модели тренда
В верхней заголовочной строке таблицы выдаются пять оценок:
Sum of Squares – сумма квадратов отклонений; df – число степеней свободы; Mean Squares – средний квадрат; F-value – критерий Фишера; p-value – расчетный уровень значимости F -критерия.
В левом столбце указывается источник вариации:
Regression – вариация, объясненная уравнением тренда; Residual – вариация остатков – отклонений фактических значений от выровненных (полученных по уравнению тренда); Total – общая вариация переменной.
На пересечении столбцов и строк получаем однозначно определенные показатели, расчетные формулы для которых представлены в табл. 3.2,
Таблица 3.2
Расчет показателей вариации трендовых моделей
| Source | df | Sum of Squares | Mean squares | F-value |
| Regression | m |  |  |  |
| Residual | n-m |  |  | |
| Total | n |  | ||
| Corrected Total | n-1 |  |  | |
| Regresion vs. Corrected Total | m | SSR | MSR |  |
где – выровненные значения уровней динамического ряда; – фактические значения уровней динамического ряда; – среднее значение уровней динамического ряда.
SSR (Regression Sum of Squares) – сумма квадратов прогнозных значений; SSE (Residual Sum of Squares) – сумма квадратов отклонений теоретических и фактических значений (для расчета остаточной, необъясненной дисперсии); SST (TotalSum of Squares) – сумма первой и второй строчки (сумма квадратов фактических значений); SSCT (Corrected TotalSum of Squares) – сумма квадратов отклонений фактических значений от средней величины (для расчета общей дисперсии); Regression vs. Corrected Total Sum of Squares – повторение первой строчки; MSR (Regression Mean Squares) – объясненная дисперсия; MSE (Residual Mean Squares) – остаточная, необъясненная дисперсия; MSCT (Mean Squares Corrected Total) – скорректированная общая дисперсия; Regression vs. Corrected Total Mean Squares – повторение первой строчки; Regression F-value – расчетное значение F -критерия; Regression vs. Corrected Total F-value – скорректированное расчетное значение F -критерия; n – число уровней ряда; m – число параметров уравнения тренда.
Далее опять же на закладке Quick (см. рис. 3.16) нажимаем кнопку Predicted values, Residuals, etc . После ее нажатия система строит таблицу, состоящую из трех столбцов (рис. 3.19).
Observed – наблюдаемые значения (то есть уровни исходного динамического ряда);
В главе 2 было рассмотрено понятие о тенденции временного ряда, т.е. тенденции динамики развития изучаемого показателя. Задача данной главы состоит в том, чтобы рассмотреть основные типы таких тенденций, их свойства, отражаемые с большей или меньшей степенью полноты уравнением линии тренда. Укажем при этом, что в отличие от простых систем механики тенденции изменения показателей сложных социальных, экономических, биологических и технических систем только с некоторым приближением отражаются тем или иным уравнением, линией тренда.
В данной главе рассматриваются далеко не все известные в математике линии и их уравнения, а лишь набор их сравнительно простых форм, который мы считаем достаточным для отображения и анализа большинства встречающихся на практике тенденций временных рядов. При этом желательно всегда выбирать из нескольких типов линий, достаточно близко выражающих тенденцию, более простую линию. Этот «принцип простоты» обоснован тем, что чем сложнее уравнение линии тренда, чем большее число параметров оно содержит, тем при равной степени приближения труднее дать надежную оценку этих параметров по ограниченному числу уровней ряда и тем больше ошибка оценки этих параметров, ошибки прогнозируемых уровней.
4.1. Прямолинейный тренд и его свойства
Самым простым типом линии тренда является прямая линия, описываемая линейным (т.е. первой степени) уравнением тренда:
где
 -
выровненные, т.е. лишенные колебаний,
уровни тренда для лет с номеромi;
-
выровненные, т.е. лишенные колебаний,
уровни тренда для лет с номеромi;
а - свободный член уравнения, численно равный среднему выровненному уровню для момента или периода времени, принятого за начало отсчета, т.е. для
t = 0;
b - средняя величина изменения уровней ряда за единицу изменения времени;
ti - номера моментов или периодов времени, к которым относятся уровни временного ряда (год, квартал, месяц, дата).
Среднее изменение уровней ряда за единицу времени - главный параметр и константа прямолинейного тренда. Следовательно, этот тип тренда подходит для отображения тенденции примерно равномерных изменений уровней: равных в среднем абсолютных приростов или абсолютных сокращений уровней за равные промежутки времени. Практика показывает, что такой характер динамики встречается достаточно часто. Причина близких к равномерному абсолютных изменений уровней ряда состоит в следующем: многие явления, как, например, урожайность сельскохозяйственных культур, численность населения региона, города, сумма дохода населения, среднее потребление какого-либо продовольственного товара и др., зависят от большого числа различных факторов. Одни из них влияют в сторону ускоренного роста изучаемого явления, другие - в сторону замедленного роста, третьи - в направлении сокращения уровней и т.д. Влияние разнонаправленных и разноускоренных (замедленных) сил факторов взаимно усредняется, частично взаимно погашается, а равнодействующая их влияний приобретает характер, близкий к равномерной тенденции. Итак, равномерная тенденция динамики (или застоя) - это результат сложения влияния большого количества факторов на изменение изучаемого показателя.
Графическое изображение прямолинейного тренда - прямая линия в системе прямоугольных координат с линейным (арифметическим) масштабом на обеих осях. Пример линейного тренда дан на рис. 4.1.
Абсолютные изменения уровней в разные годы не были точно одинаковыми, но общая тенденция сокращения численности занятых в народном хозяйстве очень хорошо отражается прямолинейным трендом. Его параметры вычислены в гл. 5 (табл. 5.3).

Основные свойства тренда в форме прямой линии таковы:
Равные изменения за равные промежутки времени;
Если средний абсолютный прирост - положительная величина, то относительные приросты или темпы прироста постепенно уменьшаются;
Если среднее абсолютное изменение - отрицательная величина, то относительные изменения или темпы сокращения постепенно увеличиваются по абсолютной величине снижения к предыдущему уровню;
Если тенденция к сокращению уровней, а изучаемая величина является по определению положительной, то среднее изменение b не может быть больше среднего уровняа;
При линейном тренде ускорение, т.е. разность абсолютных изменений за последовательные периоды, равно нулю.
Свойства линейного тренда иллюстрирует
табл. 4.1. Уравнение тренда:
 =
100 +20 *ti.
=
100 +20 *ti.
Показатели динамики при наличии тенденции сокращения уровней приведены в табл. 4.2.
Таблица 4.1
Показатели динамики при линейном тренде
к увеличению уровней
 =
100 +20 *ti.
=
100 +20 *ti.
|
Номер периода ti |
|
Темпы (цепные), % |
Ускорение |
|

Таблица 4.2
Показатели динамики при линейном тренде
сокращения уровней:
 =
200 -20 *ti.
=
200 -20 *ti.
|
Номер периода ti |
|
Абсолютное изменение к предыдущему периоду |
Темп к предыдущему периоду, % |
Ускорение |

Покажем пример подробного расчета параметров уравнения тренда на основе следующих данных (см. таблицу) с использованием калькулятора .
Линейное уравнение тренда имеет вид y = at + b.
1. Находим параметры уравнения методом наименьших квадратов
.
Система уравнений МНК:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y | y(t) | (y-y cp) 2 | (y-y(t)) 2 | (t-t p) 2 | (y-y(t)) : y |
| 1 | 17.4 | 1 | 302.76 | 17.4 | 12.26 | 895.01 | 26.47 | 30.25 | 0.3 |
| 2 | 26.9 | 4 | 723.61 | 53.8 | 18.63 | 416.84 | 68.39 | 20.25 | 0.31 |
| 3 | 23 | 9 | 529 | 69 | 25 | 591.3 | 4.02 | 12.25 | 0.0872 |
| 4 | 23.7 | 16 | 561.69 | 94.8 | 31.38 | 557.75 | 58.98 | 6.25 | 0.32 |
| 5 | 27.2 | 25 | 739.84 | 136 | 37.75 | 404.68 | 111.4 | 2.25 | 0.39 |
| 6 | 34.5 | 36 | 1190.25 | 207 | 44.13 | 164.27 | 92.72 | 0.25 | 0.28 |
| 7 | 50.7 | 49 | 2570.49 | 354.9 | 50.5 | 11.45 | 0.0383 | 0.25 | 0.0039 |
| 8 | 61.4 | 64 | 3769.96 | 491.2 | 56.88 | 198.34 | 20.44 | 2.25 | 0.0736 |
| 9 | 69.3 | 81 | 4802.49 | 623.7 | 63.25 | 483.27 | 36.56 | 6.25 | 0.0872 |
| 10 | 94.4 | 100 | 8911.36 | 944 | 69.63 | 2216.84 | 613.62 | 12.25 | 0.26 |
| 11 | 61.1 | 121 | 3733.21 | 672.1 | 76 | 189.98 | 222.11 | 20.25 | 0.24 |
| 12 | 78.2 | 144 | 6115.24 | 938.4 | 82.38 | 953.78 | 17.46 | 30.25 | 0.0534 |
| 78 | 567.8 | 650 | 33949.9 | 4602.3 | 567.8 | 7083.5 | 1272.21 | 143 | 2.41 |
Для наших данных система уравнений имеет вид:
12a 0 + 78a 1 = 567.8
78a 0 + 650a 1 = 4602.3
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = 6.37, a 1 = 5.88
Примечание: значения столбца №6 y(t) рассчитываются на основе полученного уравнения тренда. Например, t = 1: y(1) = 6.37*1 + 5.88 = 12.26
Уравнение тренда
y = 6.37 t + 5.88Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
![]()
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве тренда.
Средние значения:
![]()
![]()
![]()
Дисперсия
![]()
Среднеквадратическое отклонение
Коэффициент эластичности
![]()
Коэффициент эластичности меньше 1. Следовательно, при изменении Х на 1%, Y изменится менее чем на 1%. Другими словами - влияние Х на Y не существенно.
Коэффициент детерминации

т.е. в 82.04 % случаев влияет на изменение данных. Другими словами - точность подбора уравнения тренда - высокая
2. Анализ точности определения оценок параметров уравнения тренда
.
Дисперсия ошибки уравнения.
где m = 1 - количество влияющих факторов в модели тренда.
Стандартная ошибка уравнения.
3. Проверка гипотез относительно коэффициентов линейного уравнения тренда
.
1) t-статистика. Критерий Стьюдента.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (10;0.025) = 2.228
>
Статистическая значимость коэффициента a 0 подтверждается. Оценка параметра a 0 является значимой и тренд у временного ряда существует..
Статистическая значимость коэффициента a 1 не подтверждается.
Доверительный интервал для коэффициентов уравнения тренда
.
Определим доверительные интервалы коэффициентов тренда, которые с надежность 95% будут следующими:
(a 1 - t набл S a 1 ;a 1 + t набл S a 1)
(6.375 - 2.228*0.943; 6.375 + 2.228*0.943)
(4.27;8.48)
(a 0 - t набл S a 0 ;a 0 + t набл S a 0)
(5.88 - 2.228*6.942; 5.88 + 2.228*6.942)
(-9.59;21.35)
Так как точка 0 (ноль) лежит внутри доверительного интервала, то интервальная оценка коэффициента a 0 статистически незначима.
2) F-статистика. Критерий Фишера.
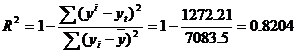
Fkp = 4.84
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Проверка на наличие автокорреляции остатков
.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция)
определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция
, нежели отрицательная автокорреляция
. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция
фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию
, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности
: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения e i с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения e i (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости e i от e i-1
Критерий Дарбина-Уотсона
.
Этот критерий является наиболее известным для обнаружения автокорреляции.
При статистическом анализе уравнения регрессии на начальном этапе часто проверяют выполнимость одной предпосылки: условия статистической независимости отклонений между собой. При этом проверяется некоррелированность соседних величин e i .
| y | y(x) | e i = y-y(x) | e 2 | (e i - e i-1) 2 |
| 17.4 | 12.26 | 5.14 | 26.47 | 0 |
| 26.9 | 18.63 | 8.27 | 68.39 | 9.77 |
| 23 | 25 | -2 | 4.02 | 105.57 |
| 23.7 | 31.38 | -7.68 | 58.98 | 32.2 |
| 27.2 | 37.75 | -10.55 | 111.4 | 8.26 |
| 34.5 | 44.13 | -9.63 | 92.72 | 0.86 |
| 50.7 | 50.5 | 0.2 | 0.0384 | 96.53 |
| 61.4 | 56.88 | 4.52 | 20.44 | 18.71 |
| 69.3 | 63.25 | 6.05 | 36.56 | 2.33 |
| 94.4 | 69.63 | 24.77 | 613.62 | 350.63 |
| 61.1 | 76 | -14.9 | 222.11 | 1574.09 |
| 78.2 | 82.38 | -4.18 | 17.46 | 115.03 |
| 1272.21 | 2313.98 |
Для анализа коррелированности отклонений используют статистику Дарбина-Уотсона
:
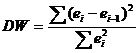
![]()
Критические значения d 1 и d 2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n = 12 и количества объясняющих переменных m=1.
Автокорреляция отсутствует, если выполняется следующее условие:
d 1 < DW и d 2 < DW < 4 - d 2 .
Не обращаясь к таблицам, можно пользоваться приблизительным правилом и считать, что автокорреляция остатков отсутствует, если 1.5 < DW < 2.5. Поскольку 1.5 < 1.82 < 2.5, то автокорреляция остатков отсутствует
.
Для более надежного вывода целесообразно обращаться к табличным значениям.
По таблице Дарбина-Уотсона для n=12 и k=1 (уровень значимости 5%) находим: d 1 = 1.08; d 2 = 1.36.
Поскольку 1.08 < 1.82 и 1.36 < 1.82 < 4 - 1.36, то автокорреляция остатков отсутствует
.
Проверка наличия гетероскедастичности
.
1) Методом графического анализа остатков
.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения e i , либо их квадраты e 2 i .
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена
.
Коэффициент ранговой корреляции Спирмена
.
Присвоим ранги признаку Y и фактору X. Найдем сумму разности квадратов d 2 .
По формуле вычислим коэффициент ранговой корреляции Спирмена.
![]()
| t | e i | ранг X, d x | ранг e i , d y | (d x - d y) 2 |
| 1 | -5.14 | 1 | 4 | 9 |
| 2 | -8.27 | 2 | 2 | 0 |
| 3 | 2 | 3 | 7 | 16 |
| 4 | 7.68 | 4 | 9 | 25 |
| 5 | 10.55 | 5 | 11 | 36 |
| 6 | 9.63 | 6 | 10 | 16 |
| 7 | -0.2 | 7 | 6 | 1 |
| 8 | -4.52 | 8 | 5 | 9 | t табл (n-m-1;α/2) = (10;0.05/2) = 2.228
Тренд (от англ. trend - тенденция ) - это долговременная тенденция изменения исследуемого временного ряда. Тренды могут быть описаны различными уравнениями - линейными, логарифмическими, степенными и так далее. Фактический тип тренда устанавливают на основе подбора его функциональной модели статистическими методами либо сглаживанием исходного временного ряда.
Тренд в экономике - это направление преимущественного движения показателей. Обычно рассматривается в рамках технического анализа, где подразумевают направленность движения цен или значений индексов. Чарльз Доу отмечал, что при восходящем тренде последующий пик на графике должен быть выше предыдущих, при нисходящем тренде последующие спады на графике должны быть ниже предыдущих.
|
Различают следующие их виды:
Выделяют тренды восходящий (бычий), нисходящий (медвежий) и боковой (флэт). На графике часто рисуют линию тренда, которая на восходящем тренде соединяет две или более впадины цены (линия находится под графиком, визуально его поддерживая и поддталкивая вверх), а на нисходящем тренде соединяет два или более пика цены (линия находится над графиком, визуально его ограничивая и придавливая вниз). Трендовые линии являются линиями поддержки (для восходящего тренда) и сопротивления (для нисходящего тренда). Понятия «бычий» и «медвежий» используются по аналогии с понятиями . Типы тренда
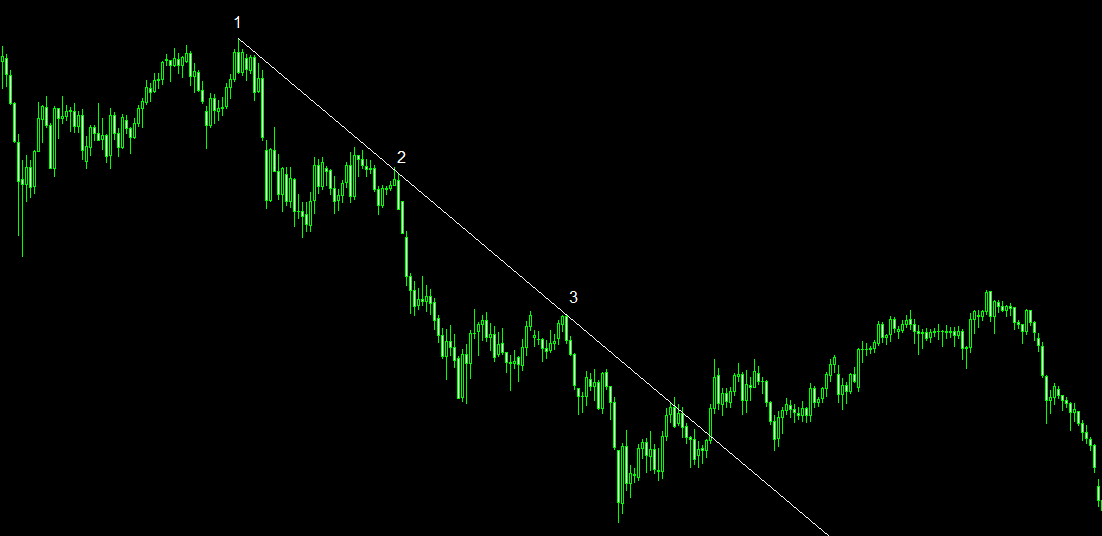
Методы оценки трендаПараметрическиеРассматривают временной ряд как гладкую функцию от t: Xt = f(t),t = 1…n;. При этом сначала выявляют один либо несколько допустимых типов функций f(t); затем различными методами (например, МНК) оценивают параметры этих функций, после чего на основе проверки критериев адекватности выбирают окончательную модель тренда. Важное значение для практических приложений имеют линеаризуемые тренды, то есть тренды, приводимые к линейному виду относительно параметров использованием тех или иных алгебраических преобразований. НепараметрическиеЭто разные методы сглаживания исходного временного ряда - скользящие средние (простая, взвешенная), экспоненциальное сглаживание. Эти методы применяются как для оценки тренда, так и для прогнозирования. Они полезны в случае, когда для оценки тренда не удается подобрать подходящую функцию. Линии трендаТрендовые линии широко используются в техническом анализе. На данный момент существует множество методов их построения и интерпретации. Линия тренда - это прямая линия, соединяющая как минимум два пика цен на графике движения курса валюты (актива). Также нужно отметить, что в пределах развития основного тренда идущего по одной линии, может формироваться множество второстепенных трендов, формирующихся по дополнительным трендовым линиям. Трендовые линии могут пробиваться ценной также как уровни поддержки и сопротивления. Показывая этим окончания текущего тренда. Существует три вида линий тренда: 1.Восходящая - строится по минимумам волн восходящего тренда и выступает в роли линии поддержки. На рисунке показана восходящая линия тренда и нижние точки, по которым она была построена 2.Нисходящая - строится по вершинам волн медвежьего тренда и выступающая в роли линии сопротивления.
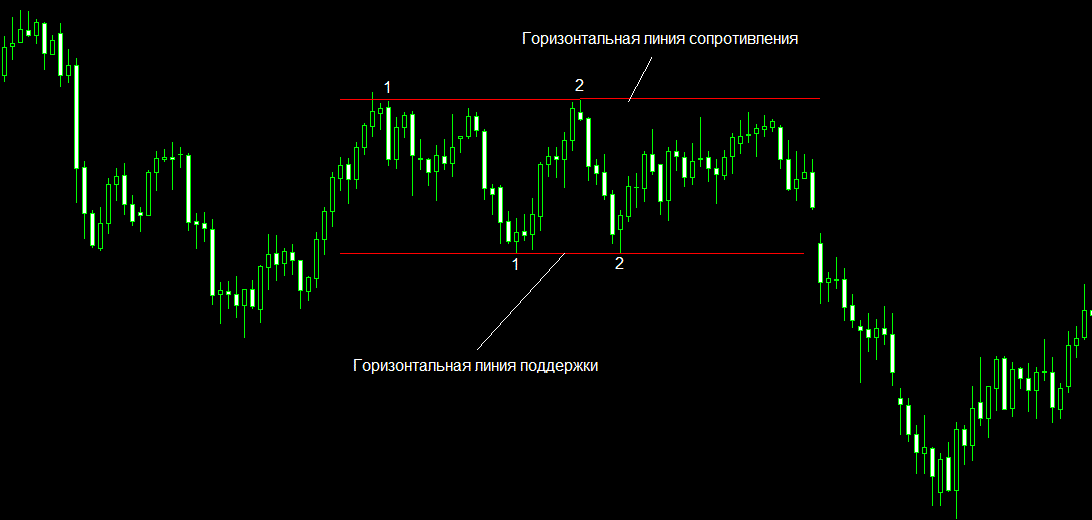
На рисунке показана нисходящая линия тренда и верхние точки, по которым она была построена 3.Горизонтальная - соединяет равные по значению максимумы или минимумы, которые зачастую поочередно меняют один одного. Такая линия рисуется при горизонтальном движении - флэте. Выступает одновременно в роли горизонтальны линий поддержки и сопротивления.
На рисунке показаны горизонтальные линии тренда и верхние/нижние точки, по которым они были построены Линии тренда классифицируются по степени важности при помощи четырех показателей:
Трендовая линия является актуальной до тех пор, пока цена не пробивает ее в противоположную текущему тренду сторону. Показывая тем самым окончание текущего тренда. |