Линейное уравнение тренда статистика. Смотреть страницы где упоминается термин линейный тренд
В трех предыдущих заметках описаны регрессионные модели, позволяющие прогнозировать отклик по значениям объясняющих переменных. В настоящей заметке мы покажем, как с помощью этих моделей и других статистических методов анализировать данные, собранные на протяжении последовательных временных интервалов. В соответствии с особенностями каждой компании, упомянутой в сценарии, мы рассмотрим три альтернативных подхода к анализу временных рядов.
Материал будет проиллюстрирован сквозным примером: прогнозирование доходов трех компаний . Представьте себе, что вы работаете аналитиком в крупной финансовой компании. Чтобы оценить инвестиционные перспективы своих клиентов, вам необходимо предсказать доходы трех компаний. Для этого вы собрали данные о трех интересующих вас компаниях - Eastman Kodak, Cabot Corporation и Wal-Mart. Поскольку компании различаются по виду деловой активности, каждый временной ряд обладает своими уникальными особенностями. Следовательно, для прогнозирования необходимо применять разные модели. Как выбрать наилучшую модель прогнозирования для каждой компании? Как оценить инвестиционные перспективы на основе результатов прогнозирования?
Обсуждение начинается с анализа ежегодных данных. Демонстрируются два метода сглаживания таких данных: скользящее среднее и экспоненциальное сглаживание. Затем демонстрируется процедура вычисления тренда с помощью метода наименьших квадратов и более сложные методы прогнозирования. В заключение, эти модели распространяются на временные ряды, построенные на основе ежемесячных или ежеквартальных данных.
Скачать заметку в формате или , примеры в формате
Прогнозирование в бизнесе
Поскольку экономические условия с течением времени изменяются, менеджеры должны прогнозировать влияние, которое эти изменения окажут на их компанию. Одним из методов, позволяющих обеспечить точное планирование, является прогнозирование. Несмотря на большое количество разработанных методов, все они преследуют одну и ту же цель - предсказать события, которые произойдут в будущем, чтобы учесть их при разработке планов и стратегии развития компании.
Современное общество постоянно испытывает необходимость в прогнозировании. Например, чтобы выработать правильную политику, члены правительства должны прогнозировать уровни безработицы, инфляции, промышленного производства, подоходного налога отдельных лиц и корпораций. Чтобы определить потребности в оборудовании и персонале, директора авиакомпаний должны правильно предсказать объем авиаперевозок. Для того чтобы создать достаточное количество мест в общежитии, администраторы колледжей или университетов хотят знать, сколько студентов поступят в их учебное заведение в следующем году.
Существуют два общепринятых подхода к прогнозированию: качественный и количественный. Методы качественного прогнозирования особенно важны, если исследователю недоступны количественные данные. Как правило, эти методы носят весьма субъективный характер. Если статистику доступны данные об истории объекта исследования, следует применять методы количественного прогнозирования. Эти методы позволяют предсказать состояние объекта в будущем на основе данных о его прошлом. Методы количественного прогнозирования разделяются на две категории: анализ временных рядов и методы анализа причинно-следственных зависимостей.
Временной ряд - это набор числовых данных, полученных в течение последовательных периодов времени. Метод анализа временных рядов позволяет предсказать значение числовой переменной на основе ее прошлых и настоящих значений. Например, ежедневные котировки акций на Нью-Йоркской фондовой бирже образуют временной ряд. Другим примером временного ряда являются ежемесячные значения индекса потребительских цен, ежеквартальные величины валового внутреннего продукта и ежегодные доходы от продаж какой-нибудь компании.
Методы анализа причинно-следственных зависимостей позволяют определить, какие факторы влияют на значения прогнозируемой переменной. К ним относятся методы множественного регрессионного анализа с запаздывающими переменными, эконометрическое моделирование, анализ лидирующих индикаторов, методы анализа диффузионных индексов и других экономических показателей. Мы расскажем лишь о методах прогнозирования на основе анализа временны х рядов.
Компоненты классической мультипликативной модели временны х рядов
Основное предположение, лежащее в основе анализа временных рядов, состоит в следующем: факторы, влияющие на исследуемый объект в настоящем и прошлом, будут влиять на него и в будущем. Таким образом, основные цели анализа временных рядов заключаются в идентификации и выделении факторов, имеющих значение для прогнозирования. Чтобы достичь этой цели, были разработаны многие математические модели, предназначенные для исследования колебаний компонентов, входящих в модель временного ряда. Вероятно, наиболее распространенной является классическая мультипликативная модель для ежегодных, ежеквартальных и ежемесячных данных. Для демонстрации классической мультипликативной модели временных рядов рассмотрим данные о фактических доходах компании Wm.Wrigley Jr. Company за период с 1982 по 2001 годы (рис. 1).
Рис. 1. График фактического валового дохода компании Wm.Wrigley Jr. Company (млн. долл. в текущих ценах) за период с 1982 по 2001 годы
Как видим, на протяжении 20 лет фактический валовой доход компании имел возрастающую тенденцию. Эта долговременная тенденция называется трендом. Тренд - не единственный компонент временного ряда. Кроме него, данные имеют циклический и нерегулярный компоненты. Циклический компонент описывает колебание данных вверх и вниз, часто коррелируя с циклами деловой активности. Его длина изменяется в интервале от 2 до 10 лет. Интенсивность, или амплитуда, циклического компонента также не постоянна. В некоторые годы данные могут быть выше значения, предсказанного трендом (т.е. находиться в окрестности пика цикла), а в другие годы - ниже (т.е. быть на дне цикла). Любые наблюдаемые данные, не лежащие на кривой тренда и не подчиняющиеся циклической зависимости, называются иррегулярными или случайными компонентами . Если данные записываются ежедневно или ежеквартально, возникает дополнительный компонент, называемый сезонным . Все компоненты временных рядов, характерных для экономических приложений, приведены на рис. 2.

Рис. 2. Факторы, влияющие на временные ряды
Классическая мультипликативная модель временного ряда утверждает, что любое наблюдаемое значение является произведением перечисленных компонентов. Если данные являются ежегодными, наблюдение Y i , соответствующее i -му году, выражается уравнением:
(1) Y i = T i * C i * I i
где T i - значение тренда, C i i -ом году, I i i -ом году.
Если данные измеряются ежемесячно или ежеквартально, наблюдение Y i , соответствующее i-му периоду, выражается уравнением:
(2) Y i = T i *S i *C i *I i
где T i - значение тренда, S i - значение сезонного компонента в i -ом периоде, C i - значение циклического компонента в i -ом периоде, I i - значение случайного компонента в i -ом периоде.
На первом этапе анализа временных рядов строится график данных и выявляется их зависимость от времени. Сначала необходимо выяснить, существует ли долговременное возрастание или убывание данных (т.е. тренд), или временной ряд колеблется вокруг горизонтальной линии. Если тренд отсутствует, то для сглаживания данных можно применить метод скользящих средних или экспоненциального сглаживания.
Сглаживание годовых временных рядов
В сценарии мы упомянули о компании Cabot Corporation. Имея штаб-квартиру в Бостоне, штат Массачусеттс, она специализируется на производстве и продаже химикатов, строительных материалов, продуктов тонкой химии, полупроводников и сжиженного природного газа. Компания имеет 39 заводов в 23 странах. Рыночная стоимость компании составляет около 1,87 млрд. долл. Ее акции котируются на Нью-Йоркской фондовой бирже под аббревиатурой СВТ. Доходы компании за указанный период приведены на рис. 3.

Рис. 3. Доходы компании Cabot Corporation в 1982–2001 годах (млрд. долл.)
Как видим, долговременная тенденция повышения доходов затемнена большим количеством колебаний. Таким образом, визуальный анализ графика не позволяет утверждать, что данные имеют тренд. В таких ситуациях можно применить методы скользящего среднего или экспоненциального сглаживания.
Скользящие средние. Метод скользящих средних весьма субъективен и зависит от длины периода L , выбранного для вычисления средних значений. Для того чтобы исключить циклические колебания, длина периода должна быть целым числом, кратным средней длине цикла. Скользящие средние для выбранного периода, имеющего длину L , образуют последовательность средних значений, вычисленных для последовательностей длины L . Скользящие средние обозначаются символами MA(L) .
Предположим, что мы хотим вычислить пятилетние скользящие средние значения по данным, измеренным в течение n = 11 лет. Поскольку L = 5, пятилетние скользящие средние образуют последовательность средних значений, вычисленных по пяти последовательным значениям временного ряда. Первое из пятилетних скользящих средних значений вычисляется путем суммирования данных о первых пяти годах с последующим делением на пять:
![]()
Второе пятилетнее скользящее среднее вычисляется путем суммирования данных о годах со 2-го по 6-й с последующим делением на пять:
![]()
Этот процесс продолжается, пока не будет вычислено скользящее среднее для последних пяти лет. Работая с годовыми данными, следует полагать число L (длину периода, выбранного для вычисления скользящих средних) нечетным. В этом случае невозможно вычислить скользящие средние для первых (L – 1)/2 и последних (L – 1)/2 лет. Следовательно, при работе с пятилетними скользящими средними невозможно выполнить вычисления для первых двух и последних двух лет. Год, для которого вычисляется скользящее среднее, должен находиться в середине периода, имеющего длину L . Если n = 11, a L = 5, первое скользящее среднее должно соответствовать третьему году, второе - четвертому, а последнее - девятому. На рис. 4 показаны графики 3- и 7-летних скользящих средних, вычисленные для доходов компании Cabot Corporation за период с 1982 по 2001 годы.

Рис. 4. Графики 3- и 7-летних скользящих средних, вычисленные для доходов компании Cabot Corporation
Обратите внимание на то, что при вычислении трехлетних скользящих средних проигнорированы наблюдаемые значения, соответствующие первому и последнему годам. Аналогично при вычислении семилетних скользящих средних нет результатов для первых и последних трех лет. Кроме того, семилетние скользящие средние намного больше сглаживают временной ряд, чем трехлетние. Это происходит потому, что семилетним скользящим средним соответствует более долгий период. К сожалению, чем больше длина периода, тем меньшее количество скользящих средних можно вычислить и представить на графике. Следовательно, больше семи лет для вычисления скользящих средних выбирать нежелательно, поскольку из начала и конца графика выпадет слишком много точек, что исказит форму временного ряда.
Экспоненциальное сглаживание. Для выявления долговременных тенденций, характеризующих изменения данных, кроме скользящих средних, применяется метод экспоненциального сглаживания. Этот метод позволяет также делать краткосрочные прогнозы (в рамках одного периода), когда наличие долговременных тенденций остается под вопросом. Благодаря этому метод экспоненциального сглаживания обладает значительным преимуществом над методом скользящих средних.
Метод экспоненциального сглаживания получил свое название от последовательности экспоненциально взвешенных скользящих средних. Каждое значение в этой последовательности зависит от всех предыдущих наблюдаемых значений. Еще одно преимущество метода экспоненциального сглаживания над методом скользящего среднего заключается в том, что при использовании последнего некоторые значения отбрасываются. При экспоненциальном сглаживании веса, присвоенные наблюдаемым значениям, убывают со временем, поэтому после выполнения вычислений наиболее часто встречающиеся значения получат наибольший вес, а редкие величины - наименьший. Несмотря на громадное количество вычислений, Excel позволяет реализовать метод экспоненциального сглаживания.
Уравнение, позволяющее сгладить временной ряд в пределах произвольного периода времени i , содержит три члена: текущее наблюдаемое значение Y i , принадлежащее временному ряду, предыдущее экспоненциально сглаженное значение E i –1 и присвоенный вес W .
(3) E 1 = Y 1 E i = WY i + (1 – W)E i–1 , i = 2, 3, 4, …
где E i – значение экспоненциально сглаженного ряда, вычисленное для i -го периода, E i –1 – значение экспоненциально сглаженного ряда, вычисленное для (i – 1)-гo периода, Y i – наблюдаемое значение временного ряда в i -ом периоде, W – субъективный вес, или сглаживающий коэффициент (0 < W < 1).
Выбор сглаживающего коэффициента, или веса, присвоенного членам ряда, является принципиально важным, поскольку он непосредственно влияет на результат. К сожалению, этот выбор до некоторой степени субъективен. Если исследователь хочет просто исключить из временного ряда нежелательные циклические или случайные колебания, следует выбирать небольшие величины W (близкие к нулю). С другой стороны, если временной ряд используется для прогнозирования, необходимо выбрать большой вес W (близкий к единице). В первом случае четко проявляются долговременные тенденции временного ряда. Во втором случае повышается точность краткосрочного прогнозирования (рис. 5).

Рис. 5 Графики экспоненциально сглаженного временного ряда (W=0,50 и W=0,25) для данных о доходах компании Cabot Corporation за период с 1982 по 2001 годы; формулы расчета см. в файле Excel
Экспоненциально сглаженное значение, полученное для i -го временного интервала, можно использовать в качестве оценки предсказанного значения в (i +1)-м интервале:
![]()
Для предсказания доходов компании Cabot Corporation в 2002 году на основе экспоненциально сглаженного временного ряда, соответствующего весу W = 0,25, можно использовать сглаженное значение, вычисленное для 2001 года. Из рис. 5 видно, что эта величина равна 1651,0 млн. долл. Когда станут доступными данные о доходах компании в 2002 году, можно применить уравнение (3) и предсказать уровень доходов в 2003 году, используя сглаженное значение доходов в 2002 году:
Пакет анализа Excel способен построить график экспоненциального сглаживания в один клик. Пройдите по меню Данные → Анализ данных и выберите опцию Экспоненциальное сглаживание (рис. 6). В открывшемся окне Экспоненциальное сглаживание задайте параметры. К сожалению, процедура позволяет построить только один сглаженный ряд, поэтому, если вы хотите «поиграть» с параметром W , повторите процедуру.

Рис. 6. Построение графика экспоненциального сглаживания с помощью Пакета анализа
Вычисление трендов с помощью метода наименьших квадратов и прогнозирование
Среди компонентов временного ряда чаще других исследуется тренд. Именно тренд позволяет делать краткосрочные и долгосрочные прогнозы. Для выявления долговременной тенденции изменения временного ряда обычно строят график, на котором наблюдаемые данные (значения зависимой переменной) откладываются на вертикальной оси, а временные интервалы (значения независимой переменной) - на горизонтальной. В этом разделе мы опишем процедуру выявления линейного, квадратичного и экспоненциального тренда с помощью метода наименьших квадратов.
Модель линейного тренда является простейшей моделью, применяемой для прогнозирования: Y i = β 0 + β 1 X i + ε i . Уравнение линейного тренда:
![]()
При заданном уровне значимости α нулевая гипотеза отклоняется, если тестовая t -статистика больше верхнего или меньше нижнего критического уровня t -распределения. Иначе говоря, решающее правило формулируется следующим образом: если t > t U или t < t L , нулевая гипотеза Н 0 отклоняется, в противном случае нулевая гипотеза не отклоняется (рис. 14).

Рис. 14. Области отклонения гипотезы для двустороннего критерия значимости параметра авторегрессии А р , имеющего наивысший порядок
Если нулевая гипотеза (А р = 0) не отклоняется, значит, выбранная модель содержит слишком много параметров. Критерий позволяет отбросить старший член модели и оценить авторегрессионную модель порядка р–1 . Эту процедуру следует продолжать до тех пор, пока нулевая гипотеза Н 0 не будет отклонена.
- Выберите порядок р оцениваемой авторегрессионной модели с учетом того, что t -критерий значимости имеет n –2р–1 степеней свободы.
- Сформируйте последовательность переменных р «с запаздыванием» так, чтобы первая переменная запаздывала на один временной интервал, вторая - на два и так далее. Последнее значение должно запаздывать на р временных интервалов (см. рис. 15).
- Примените Пакет анализа Excel для вычисления регрессионной модели, содержащей все р значений временного ряда с запаздыванием.
- Оцените значимость параметра А Р , имеющего наивысший порядок: а) если нулевая гипотеза отклоняется, в авторегрессионную модель можно включать все р параметров; б) если нулевая гипотеза не отклоняется, отбросьте р -ю переменную и повторите п.3 и 4 для новой модели, включающей р–1 параметр. Проверка значимости новой модели основана на t -критерии, количество степеней свободы определяется новым количеством параметров.
- Повторяйте п.3 и 4, пока старший член авторегрессионной модели не станет статистически значимым.
Чтобы продемонстрировать авторегрессионное моделирование, вернемся к анализу временного ряда реальных доходов компании Wm. Wrigley Jr. На рис. 15 показаны данные, необходимые для построения авторегрессионных моделей первого, второго и третьего порядка. Для построения модели третьего порядка необходимы все столбцы этой таблицы. При построении авторегрессионной модели второго порядка последний столбец игнорируется. При построении авторегрессионной модели первого порядка игнорируются два последних столбца. Таким образом, при построении авторегрессионных моделей первого, второго и третьего порядка из 20 переменных исключаются одна, две и три соответственно.

Выбор наиболее точной авторегрессионной модели начинается с модели третьего порядка. Для корректной работы Пакета анализа следует в качестве входного интервала Y указать диапазон В5:В21, а входного интервала для Х – С5:Е21. Данные анализа приведены на рис. 16.

Проверим значимость параметра А 3 , имеющего наивысший порядок. Его оценка а 3 равна –0,006 (ячейка С20 на рис. 16), а стандартная ошибка равна 0,326 (ячейка D20). Для проверки гипотез Н 0: А 3 = 0 и Н 1: А 3 ≠ 0 вычислим t -статистику:

t -критерия с n–2p–1 = 20–2*3–1 = 13 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;13) = –2,160; t U =СТЬЮДЕНТ.ОБР(0,975;13) = +2,160. Поскольку –2,160 < t = –0,019 < +2,160 и р = 0,985 > α = 0,05, нулевую гипотезу Н 0 отклонять нельзя. Таким образом, параметр третьего порядка не имеет статистической значимости в авторегрессионной модели и должен быть удален.
Повторим анализ для авторегрессионной модели второго порядка (рис. 17). Оценка параметра, имеющего наивысший порядок, а 2 = –0,205, а ее стандартная ошибка равна 0,276. Для проверки гипотез Н 0: А 2 = 0 и Н 1: А 2 ≠ 0 вычислим t -статистику:


При уровне значимости α = 0,05, критические величины двухстороннего t -критерия с n–2p–1 = 20–2*2–1 = 15 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;15) = –2,131; t U =СТЬЮДЕНТ.ОБР(0,975;15) = +2,131. Поскольку –2,131 < t = –0,744 < –2,131 и р = 0,469 > α = 0,05, нулевую гипотезу Н 0 отклонять нельзя. Таким образом, параметр второго порядка не является статистически значимым, и его следует удалить из модели.
Повторим анализ для авторегрессионной модели первого порядка (рис. 18). Оценка параметра, имеющего наивысший порядок, а 1 = 1,024, а ее стандартная ошибка равна 0,039. Для проверки гипотез Н 0: А 1 = 0 и Н 1: А 1 ≠ 0 вычислим t -статистику:


При уровне значимости α = 0,05, критические величины двухстороннего t -критерия с n–2p–1 = 20–2*1–1 = 17 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;17) = –2,110; t U =СТЬЮДЕНТ.ОБР(0,975;17) = +2,110. Поскольку –2,110 < t = 26,393 < –2,110 и р = 0,000 < α = 0,05, нулевую гипотезу Н 0 следует отклонить. Таким образом, параметр первого порядка является статистически значимым, и его нельзя удалять из модели. Итак, модель авторегрессии первого порядка лучше других аппроксимирует исходные данные. Используя оценки а 0 = 18,261, а 1 = 1,024 и значение временного ряда за последний год - Y 20 = 1 371,88, можно предсказать величину реальных доходов компании Wm. Wrigley Jr. Company в 2002 г.:
Выбор адекватной модели прогнозирования
Выше были описаны шесть методов прогнозирования значений временного ряда: модели линейного, квадратичного и экспоненциального трендов и авторегрессионные модели первого, второго и третьего порядков. Существует ли оптимальная модель? Какую из шести описанных моделей следует применять для прогнозирования значения временного ряда? Ниже перечислены четыре принципа, которыми необходимо руководствоваться при выборе адекватной модели прогнозирования. Эти принципы основаны на оценках точности моделей. При этом предполагается, что значения временного ряда можно предсказать, изучая его предыдущие значения.
Принципы выбора моделей для прогнозирования:
- Выполните анализ остатков.
- Оцените величину остаточной ошибки с помощью квадратов разностей.
- Оцените величину остаточной ошибки с помощью абсолютных разностей.
- Руководствуйтесь принципом экономии.
Анализ остатков. Напомним, что остатком называется разность между предсказанным и наблюдаемым значением. Построив модель для временного ряда, следует вычислить остатки для каждого из n интервалов. Как показано на рис. 19, панель А, если модель является адекватной, остатки представляют собой случайный компонент временного ряда и, следовательно, распределены нерегулярно. С другой стороны, как показано на остальных панелях, если модель не адекватна, остатки могут иметь систематическую зависимость, не учитывающую либо тренд (панель Б), либо циклический (панель В), либо сезонный компонент (панель Г).

Рис. 19. Анализ остатков
Измерение абсолютной и среднеквадратичной остаточных погрешностей. Если анализ остатков не позволяет определить единственную адекватную модель, можно воспользоваться другими методами, основанными на оценке величины остаточной погрешности. К сожалению, статистики не пришли к консенсусу относительно наилучшей оценки остаточных погрешностей моделей, применяемых для прогнозирования. Исходя из принципа наименьших квадратов, можно сначала провести регрессионный анализ и вычислить стандартную ошибку оценки S XY . При анализе конкретной модели эта величина представляет собой сумму квадратов разностей между фактическим и предсказанным значениями временного ряда. Если модель идеально аппроксимирует значения временного ряда в предыдущие моменты времени, стандартная ошибка оценки равна нулю. С другой стороны, если модель плохо аппроксимирует значения временного ряда в предыдущие моменты времени, стандартная ошибка оценки велика. Таким образом, анализируя адекватность нескольких моделей, можно выбрать модель, имеющую минимальную стандартную ошибку оценки S XY .
Основным недостатком такого подхода является преувеличение ошибок при прогнозировании отдельных значений. Иначе говоря, любая большая разность между величинами Y i и Ŷ i при вычислении суммы квадратов ошибок SSE возводится в квадрат, т.е. увеличивается. По этой причине многие статистики предпочитают применять для оценки адекватности модели прогнозирования среднее абсолютное отклонение (mean absolute deviation - MAD):

При анализе конкретных моделей величина MAD представляет собой среднее значение модулей разностей между фактическим и предсказанными значениями временного ряда. Если модель идеально аппроксимирует значения временного ряда в предыдущие моменты времени, среднее абсолютное отклонение равно нулю. С другой стороны, если модель плохо аппроксимирует такие значения временного ряда, среднее абсолютное отклонение велико. Таким образом, анализируя адекватность нескольких моделей, можно выбрать модель, имеющую минимальное среднее абсолютное отклонение.
Принцип экономии. Если анализ стандартных ошибок оценок и средних абсолютных отклонений не позволяет определить оптимальную модель, можно воспользоваться четвертым методом, основанным на принципе экономии. Этот принцип утверждает, что из нескольких равноправных моделей следует выбирать простейшую.
Среди шести рассмотренных в главе моделей прогнозирования наиболее простыми являются линейная и квадратичная регрессионные модели, а также авторегрессионная модель первого порядка. Остальные модели намного сложнее.
Сравнение четырех методов прогнозирования. Для иллюстрации процесса выбора оптимальной модели вернемся к временному ряду, состоящему из величин реального дохода компании Wm. Wrigley Jr. Company. Сравним четыре модели: линейную, квадратичную, экспоненциальную и авторегрессионную модель первого порядка. (Авторегрессионные модели второго и третьего порядка лишь незначительно улучшают точность прогнозирования значений данного временного ряда, поэтому их можно не рассматривать.) На рис. 20 показаны графики остатков, построенные при анализе четырех методов прогнозирования с помощью Пакета анализа Excel. Делая выводы на основе этих графиков, следует быть осторожным, поскольку временной ряд содержит только 20 точек. Методы построения см. соответствующий лист Excel-файла.

Рис. 20. Графики остатков, построенные при анализе четырех методов прогнозирования с помощью Пакета анализа Excel
Ни одна модель, кроме авторегрессионой модели первого порядка, не учитывает циклический компонент. Именно эта модель лучше других аппроксимирует наблюдения и характеризуется наименее систематической структурой. Итак, анализ остатков всех четырех методов показал, что наилучшей является авторегрессионная модель первого порядка, а линейная, квадратичная и экспоненциальная модели имеют меньшую точность. Чтобы убедиться в этом, сравним величины остаточных погрешностей этих методов (рис. 21). С методикой расчетов можно ознакомиться, открыв Excel-файл. На рис. 21 указаны фактические значения Y i (колонка Реальный доход ), предсказанные значения Ŷ i , а также остатки е i для каждой из четырех моделей. Кроме того, показаны значения S YX и MAD . Для всех четырех моделей величинs S YX и MAD примерно одинаковые. Экспоненциальная модель является относительно худшей, а линейная и квадратичная модели превосходят ее по точности. Как и ожидалось, наименьшие величины S YX и MAD имеет авторегрессионная модель первого порядка.

Рис. 21. Сравнение четырех методов прогнозирования с помощью показателей S YX и MAD
Выбрав конкретную модель прогнозирования, необходимо внимательно следить за дальнейшими изменениями временного ряда. Помимо всего прочего, такая модель создается, чтобы правильно предсказывать значения временного ряда в будущем. К сожалению, такие модели прогнозирования плохо учитывают изменения в структуре временного ряда. Совершенно необходимо сравнивать не только остаточную погрешность, но и точность прогнозирования будущих значений временного ряда, полученную с помощью других моделей. Измерив новую величину Y i в наблюдаемом интервале времени, ее необходимо тотчас же сравнить с предсказанным значением. Если разница слишком велика, модель прогнозирования следует пересмотреть.
Прогнозирование временны х рядов на основе сезонных данных
До сих пор мы изучали временные ряды, состоящие из годовых данных. Однако многие временные ряды состоят из величин, измеряемых ежеквартально, ежемесячно, еженедельно, ежедневно и даже ежечасно. Как показано на рис. 2, если данные измеряются ежемесячно или ежеквартально, следует учитывать сезонный компонент. В этом разделе мы рассмотрим методы, позволяющие прогнозировать значения таких временных рядов.
В сценарии, описанном в начале главы, упоминалась компания Wal-Mart Stores, Inc. Рыночная капитализация компании 229 млрд. долл. Ее акции котируются на Нью-Йоркской фондовой бирже под аббревиатурой WMT. Финансовый год компании заканчивается 31 января, поэтому в четвертый квартал 2002 года включаются ноябрь и декабрь 2001 года, а также январь 2002 года. Временной ряд квартальных доходов компании приведен на рис. 22.

Рис. 22. Квартальные доходы компании Wal-Mart Stores, Inc. (млн. долл.)
Для таких квартальных рядов, как этот, классическая мультипликативная модель, кроме тренда, циклического и случайного компонента, содержит сезонный компонент: Y i = T i * S i * C i * I i
Прогнозирование месячных и временны х рядов с помощью метода наименьших квадратов. Регрессионная модель, включающая сезонный компонент, основана на комбинированном подходе. Для вычисления тренда применяется метод наименьших квадратов, описанный ранее, а для учета сезонного компонента - категорийная переменная (подробнее см. раздел Регрессионные модели с фиктивной переменной и эффекты взаимодействия ). Для аппроксимации временных рядов с учетом сезонных компонентов используется экспоненциальная модель. В модели, аппроксимирующей квартальный временной ряд, для учета четырех кварталов нам понадобились три фиктивные переменные Q 1 , Q 2 и Q 3 , а в модели для месячного временного ряда 12 месяцев представляются с помощью 11 фиктивных переменных. Поскольку в этих моделях в качестве отклика используется переменная logY i , а не Y i , для вычисления настоящих регрессионных коэффициентов необходимо выполнить обратное преобразование.
Чтобы проиллюстрировать процесс построения модели, аппроксимирующей квартальный временной ряд, вернемся к доходам компании Wal-Mart. Параметры экспоненциальной модели, полученные с помощью Пакета анализа Excel, показаны на рис. 23.

Рис. 23. Регрессионный анализ квартальных доходов компании Wal-Mart Stores, Inc.
Видно, что экспоненциальная модель довольно хорошо аппроксимирует исходные данные. Коэффициент смешанной корреляции r 2 равен 99,4% (ячейки J5), скорректированный коэффициент смешанной корреляции - 99,3% (ячейки J6), тестовая F -статистика - 1 333,51 (ячейки M12), а р -значение равно 0,0000. При уровне значимости α = 0,05, каждый регрессионный коэффициент в классической мультипликативной модели временного ряда является статистически значимым. Применяя к ним операцию потенцирования, получаем следующие параметры:

Коэффициенты ![]() интерпретируются следующим образом.
интерпретируются следующим образом.
Используя регрессионные коэффициенты b i , можно предсказать доход, полученный компанией в конкретном квартале. Например, предскажем доход компании для четвертого квартала 2002 года (X i = 35):
log = b 0 + b 1 Х i = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Таким образом, согласно прогнозу в четвертом квартале 2002 года компания должна была получить доход, равный 67 млрд. долл. (вряд ли следует делать прогноз с точностью до миллиона). Для того чтобы распространить прогноз на период времени, находящийся за пределами временного ряда, например, на первый квартал 2003 года (X i = 36, Q 1 = 1), необходимо выполнить следующие вычисления:
logŶ i = b 0 + b 1 Х i + b 2 Q 1 = 4,265 + 0,016*36 – 0,093*1 = 4,748
10 4,748 = 55 976
Индексы
Индексы используются в качестве индикаторов, реагирующих на изменения экономической ситуации или деловой активности. Существуют многочисленные разновидности индексов, в частности, индексы цен, количественные индексы, ценностные индексы и социологические индексы. В данном разделе мы рассмотрим лишь индекс цен. Индекс - величина некоторого экономического показателя (или группы показателей) в конкретный момент времени, выраженный в процентах от его значения в базовый момент времени.
Индекс цен. Простой индекс цен отражает процентное изменение цены товара (или группы товаров) в течение заданного периода времени по сравнению с ценой этого товара (или группы товаров) в конкретный момент времени в прошлом. При вычислении индекса цен прежде всего следует выбрать базовый промежуток времени - интервал времени в прошлом, с которым будут производиться сравнения. При выборе базового промежутка времени для конкретного индекса периоды экономической стабильности являются более предпочтительными по сравнению с периодами экономического подъема или спада. Кроме того, базовый промежуток не должен быть слишком удаленным во времени, чтобы на результаты сравнения не слишком сильно влияли изменения технологии и привычек потребителей. Индекс цен вычисляется по формуле:

где I i - индекс цен в i -м году, Р i - цена в i -м году, Р баз - цена в базовом году.
Индекс цен - процентное изменение цены товара (или группы товаров) в заданный период времени по отношению к цене товара в базовый момент времени. В качестве примера рассмотрим индекс цен на неэтилированный бензин в США в промежутке времени с 1980 по 2002 г. (рис. 24). Например:


Рис. 24. Цена галлона неэтилированного бензина и простой индекс цен в США с 1980 по 2002 г. (базовые годы - 1980 и 1995)
Итак, в 2002 г. цена неэтилированного бензина в США была на 4,8% больше, чем в 1980 г. Анализ рис. 24 показывает, что индекс цен в 1981 и 1982 гг. был больше индекса цен в 1980 г., а затем вплоть до 2000 года не превышал базового уровня. Поскольку в качестве базового периода выбран 1980 г., вероятно, имеет смысл выбрать более близкий год, например, 1995 г. Формула для пересчета индекса по отношению к новому базовому промежутку времени:

где I новый - новый индекс цен, I старый - старый индекс цен, I новая база – значение индекса цен в новом базовом году при расчете для старого базового года.
Предположим, что в качестве новой базы выбран 1995 год. Используя формулу (10), получаем новый индекс цен для 2002 года:
Итак, в 2002 г. неэтилированный бензин в США стоил на 13,9% больше, чем в 1995 г.
Невзвешенные составные индексы цен. Несмотря на то что индекс цен на любой отдельный товар представляет несомненный интерес, более важным является индекс цен на группу товаров, позволяющий оценить стоимость и уровень жизни большого количества потребителей. Невзвешенный составной индекс цен, определенный формулой (11), приписывает каждому отдельному виду товаров одинаковый вес. Составной индекс цен отражает процентное изменение цены группы товаров (часто называемой потребительской корзиной) в заданный период времени по отношению к цене этой группы товаров в базовый момент времени.

где t i - номер товара (1, 2, …, n ), n - количество товаров в рассматриваемой группе, - сумма цен на каждый из n товаров в период времени t , - сумма цен на каждый из n товаров в нулевой период времени, - величина невзвешенного составного индекса в период времени t .
На рис. 25 представлены средние цены на три вида фруктов за период с 1980 по 1999 гг. Для вычисления невзвешенного составного индекса цен в разные годы применяется формула (11), считая базовым 1980 год.
Итак, в 1999 г. суммарная цена фунта яблок, фунта бананов и фунта апельсинов на 59,4% превышала суммарную цену на эти фрукты в 1980 г.

Рис. 25. Цены (в долл.) на три вида фруктов и невзвешенный составной индекс цен
Невзвешенный составной индекс цен выражает изменения цен на всю группу товаров с течением времени. Несмотря на то что этот индекс легко вычислять, у него есть два явных недостатка. Во-первых, при вычислении этого индекса все виды товаров считаются одинаково важными, поэтому дорогие товары приобретают излишнее влияние на индекс. Во-вторых, не все товары потребляются одинаково интенсивно, поэтому изменения цен на мало потребляемые товары слишком сильно влияют на невзвешенный индекс.
Взвешенные составные индексы цен. Из-за недостатков невзвешенных индексов цен более предпочтительными являются взвешенные индексы цен, учитывающие различия цен и уровней потребления товаров, образующих потребительскую корзину. Существуют два типа взвешенных составных индексов цен. Индекс цен Лапейрэ , определенный формулой (12), использует уровни потребления в базовом году. Взвешенный составной индекс цен позволяет учесть уровни потребления товаров, образующих потребительскую корзину, присваивая каждому товару определенный вес.

где t - период времени (0, 1, 2, …), i - номер товара (1, 2, …, n ), n i в нулевой период времени, - значение индекса Лапейрэ в период времени t .
Вычисления индекса Лапейрэ показаны на рис. 26; в качестве базового используется 1980 год.

Рис. 26. Цены (в долл.), количество (потребление в фунтах на душу населения) трех видов фруктов и индекс Лапейрэ
Итак, индекс Лапейрэ в 1999 г. равен 154,2. Это свидетельствует от том, что в 1999 году эти три вида фруктов были на 54,2% дороже, чем в 1980 году. Обратите внимание на то, что этот индекс меньше невзвешенного индекса, равного 159,4, поскольку цены на апельсины - фрукты, потребляемые меньше остальных, - выросли больше, чем цена яблок и бананов. Иначе говоря, поскольку цены на фрукты, потребляемые наиболее интенсивно, выросли меньше, чем цены на апельсины, индекс Лапейрэ меньше невзвешенного составного индекса.
Индекс цен Пааше использует уровни потребления товара в текущем, а не базовом периоде времени. Следовательно, индекс Пааше более точно отражает полную стоимость потребления товаров в заданный момент времени. Однако этот индекс имеет два существенных недостатка. Во-первых, как правило, текущие уровни потребления трудно определить. По этой причине многие популярные индексы используют индекс Лапейрэ, а не индекс Пааше. Во-вторых, если цена некоторого конкретного товара, входящего в потребительскую корзину, резко возрастает, покупатели снижают уровень его потребления по необходимости, а не вследствие изменения вкусов. Индекс Пааше вычисляется по формуле:

где t - период времени (0, 1, 2, …), i - номер товара (1, 2, …, n ), n - количество товаров в рассматриваемой группе, - количество единиц товара i в нулевой период времени, - значение индекса Пааше в период времени t .
Вычисления индекса Пааше показаны на рис. 27; в качестве базового используется 1980 год.

Рис. 27. Цены (в долл.), количество (потребление в фунтах на душу населения) трех видов фруктов и индекс Пааше
Итак, индекс Пааше в 1999 г. равен 147,0. Это свидетельствует от том, что в 1999 году эти три вида фруктов были на 47,0% дороже, чем в 1980 году.
Некоторые популярные индексы цен. В бизнесе и экономике используется несколько индексов цен. Наиболее популярным является индекс потребительских цен (Consumer Index Price - CPI). Официально этот индекс называется CPI-U, чтобы подчеркнуть, что он вычисляется для городов (urban), хотя, как правило, его называют просто CPI. Этот индекс ежемесячно публикуется Бюро статистики труда (U. S. Bureau of Labor Statistics) в качестве основного инструмента для измерения стоимости жизни в США. Индекс потребительских цен является составным и взвешенным по методу Лапейрэ. При его вычислении используются цены 400 наиболее широко потребляемых продуктов, видов одежды, транспортных, медицинских и коммунальных услуг. В данный момент при вычислении этого индекса в качестве базового используется период 1982–1984 гг. (рис. 28). Важной функцией индекса CPI является его использование в качестве дефлятора. Индекс CPI используется для пересчета фактических цен в реальные путем умножения каждой цены на коэффициент 100/CPI. Расчеты показывают, что за последние 30 лет среднегодовые темпы инфляции в США составили 2,9%.

Рис. 28. Динамика Consumer Index Price; полные данные см. Excel-файл
Другим важным индексом цен, публикуемым Бюро статистики труда, является индекс цен производителей (Producer Price Index - PPI). Индекс PPI является взвешенным составным индексом, использующим метод Лапейрэ для оценки изменения цен товаров, продаваемых их производителями. Индекс PPI является лидирующим индикатором для индекса CPI. Иначе говоря, увеличение индекса PPI приводит к увеличению индекса CPI, и наоборот, уменьшение индекса PPI приводит к уменьшению индекса CPI. Финансовые индексы, такие как индекс Доу-Джонса для акций промышленных предприятий (Dow Jones Industrial Average - DJIA), S&P 500 и NASDAQ, используются для оценки изменения стоимости акций в США. Многие индексы позволяют оценить прибыльность международных фондовых рынков. К таким индексам относятся индекс Nikkei в Японии, Dax 30 в Германии и SSE Composite в Китае.
Ловушки, связанные с анализом временны х рядов
Значение методологии, использующей информацию о прошлом и настоящем для того, чтобы прогнозировать будущее, более двухсот лет назад красноречиво описал государственный деятель Патрик Генри: «У меня есть лишь одна лампа, освещающая путь, - мой опыт. Только знание прошлого позволяет судить о будущем».
Анализ временных рядов основан на предположении, что факторы, влиявшие на деловую активность в прошлом и влияющие в настоящем, будут действовать и в будущем. Если это правда, анализ временных рядов представляет собой эффективное средство прогнозирования и управления. Однако критики классических методов, основанных на анализе временных рядов, утверждают, что эти методы слишком наивны и примитивны. Иначе говоря, математическая модель, учитывающая факторы, действовавшие в прошлом, не должна механически экстраполировать тренды в будущее без учета экспертных оценок, опыта деловой активности, изменения технологии, а также привычек и потребностей людей. Пытаясь исправить это положение, в последние годы специалисты по эконометрии разрабатывали сложные компьютерные модели экономической активности, учитывающие перечисленные выше факторы.
Тем не менее, методы анализа временных рядов представляют собой превосходный инструмент прогнозирования (как краткосрочного, так и долгосрочного), если они применяются правильно, в сочетании с другими методами прогнозирования, а также с учетом экспертных оценок и опыта.
Резюме. В заметке с помощью анализа временных рядов разработаны модели для прогнозирования доходов трех компаний: Wm. Wrigley Jr. Company, Cabot Corporation и Wal-Mart. Описаны компоненты временного ряда, а также несколько подходов к прогнозированию годовых временных рядов - метод скользящих средних, метод экспоненциального сглаживания, линейная, квадратичная и экспоненциальная модели, а также авторегрессионная модель. Рассмотрена регрессионная модель, содержащая фиктивные переменные, соответствующие сезонному компоненту. Показано применение метода наименьших квадратов для прогнозирования месячных и квартальных временных рядов (рис. 29).
Р степеней свободы утрачиваются при сравнении значений временного ряда.
При использовании полиномов разных степеней оценка параметров уравнения тренда производится методом наименьших квадратов (МНК) точно так же, как оценки параметров уравнения регрессии на основе пространственных данных. В качестве зависимой переменной рассматриваются уровни динамического ряда, а в качестве независимой переменной – фактор времени t, который обычно выражается рядом натуральных чисел 1, 2, ..., п.
Оценка параметров нелинейных функций проводится МНК после линеаризации, т.е. приведения их к линейному виду. Рассмотрим применение МНК для некоторых нелинейных функций, которые не излагались подробно в главе, посвященной регрессии.
Для оценки параметров показательной кривой у = ab 1 или экспоненты у = е а+ы (либо у = ае ы) путем логарифмирования функции приводятся к линейному виду lny = ln a + t ln b или экспоненты: lny = a + bt. Далее строится система нормальных уравнений
Пример 5.1
Число зарегистрированных ДТП (на 100 000 человек населения) по Новгородской области за 2000–2008 гг. характеризуется данными:
Исходя из графика была выбрана показательная кривая / Для построения системы нормальных уравнений были рассчитаны вспомогательные величины

Система нормальных уравнений составила ![]()
Решая ее, получим значения
![]()
Соответственно имеем экспоненту или показательную кривую
За период с 2000 по 2008 г. число дорожно-транспортных происшествий возрастало в среднем ежегодно на 13,5%. Экспонента достаточно хорошо описывает тенденцию исходного временного ряда: коэффициент детерминации составил 0,9202. Следовательно, данный тренд объясняет 92% колеблемости уровней ряда и лишь 8% ее связаны со случайными факторами.
Некоторую специфику имеет оценка параметров кривых с насыщением: модификационной экспоненты, логистической кривой, кривой Гомперца, гиперболы вида По этим функциям должна быть сначала определена асимптота. Если она может быть задана исследователем на основе анализа временного ряда, то другие параметры могут быть оценены по МНК. В этих случаях данные функции приводятся к линейному виду. Рассмотрим оценку параметров этих кривых на отдельных примерах, начиная с модифицированной экспоненты.
Пример 5.2
Уровень механизации труда (в %) характеризуется динамическим рядом (табл. 5.2)
Таблица 5.2. Расчет параметров модифицированной экспоненты у = с ab" t
|
У = с-у |
|||||||
Так как уровень механизации труда не может превышать 100%, то имеется объективно заданная верхняя асимптота с = 100. Для оценки параметров а и b приведем рассматриваемую функцию к линейному виду ; обозначим (с-у) через Y и прологарифмируем:
![]()
Для нашего примера, исходя из данных итоговой строки табл. 3, имеем систему уравнений
![]()
Решив ее, получим ln а = 3,06311; ln b = -0,19744. Соответственно потенцируя, получим: т.е. уравнение .
Если перейти от Y к исходным уровням ряда, уравнение модифицированной экспоненты составит , где параметр показывает средний коэффициент снижения уровня использования ручного труда за 1998–2005 гг. Расчетные значения у, т.е. могут быть найдены путем подстановки в уравнение 0,8208" соответствующих значений t. Либо на основе уравнения In 7= 3,06311 – 0,19744 г при компьютерной обработке определяется In У и далее 100 – е 1пу. Так, при t = 8 In Y = = 1,48363 и 100 – e1"48363 = 100 – 4,40892 = 95,59108 = 95,6 (см. последнюю графу таблицы). Ввиду некоторой смещенности оценок (так как МНК применяется к логарифмам) Ху, Ф Ху, хотя в примере эти величины достаточно близки друг другу.
Если асимптота с не задана, то оценка параметров модифицированной экспоненты усложняется. В этих случаях могут использоваться разные методы оценивания: метод трех сумм, метод трех точек , с помощью регрессии , метод Брианта . Рассмотрим применение метода регрессии для оценки параметров модифицированной экспоненты вида у = с – ab c.
Пример 5.3
В таблице представлены данные о расходах предприятия на рекламу за 10 мес. года.
Таблица 5.3. Данные о расходах предприятия на рекламу за 10 мес. года (в тыс. руб.)
Найдем по нашему ряду цепные абсолютные приростыг и представим их через параметры нашей функции, T.e.z = c-ab" – с + ab"~ l = ab" 1 (1 – b). Известно, что для модифицированной экспоненты логарифм абсолютных приростов линейно зависит от фактора времени t. Следовательно, можно записать, что lnz = Ιηα + (f – 1) lnb + ln(l – b). Обозначим Ιηα + ln(l – b) через d. Тогда lnz = d + (t- 1) lnb, т.е. линейное в логарифмах уравнение. Применяя МНК, получим оценки параметров d, lnb, а соответственно и параметра Ь. В рассматриваемом примере на основании граф табл. 5.3 lnz и (t – 1) было найдено уравнение регрессии: lnz = 4,519641 – 0,20882 (t – 1). Исходя из него получаем lnb = -0,20882; b = 0,811538. 4,519641 = In a + In (1 – b) = In [α (1 – b)]. Тогда α (1 – b) = e4,519641, откуда параметра =91,80264/(1-0,811538) = 487,1145.
Далее можно найти оценку параметра с как среднее значение из величин с = у + ab", найденных для каждого месяца (см. последнюю графу табл. 5.3). Предельная величина расходов на рекламу составит 516,4 тыс. руб. Искомое уравнение тренда примет вид
Рассмотренный метод применим, если абсолютные приросты – величины положительные. Если же некоторые приросты окажутся меньше нуля, то нужно проводить сглаживание уровней временного ряда методом скользящей средней.
Для логистической кривой Перла – Рида аналогично параметры а и b могут быть найдены МНК, если асимптота с задана. Тогда данная функция преобразовывается в линейную из логарифмов ![]() обозначим через Y
и прологарифмируем, т.е. ). Далее параметры а и b
определяются МНК, как и в примере по табл. 5.3.
обозначим через Y
и прологарифмируем, т.е. ). Далее параметры а и b
определяются МНК, как и в примере по табл. 5.3.
Для логистической кривой вида параметры а и b могут быть оценены МНК, если асимптота с задана, так как в этом случае функция линеаризуема: ; обозначим через Y величину и прологарифмируем: Далее, применяя МНК, оцениваем параметры а и b.
При практических расчетах значение верхней асимптоты логистической кривой может быть определено исходя из существа развития явления, различного рода ограничений для его роста (нормативы потребления, законодательные акты), а также графически.
Если верхняя асимптота не задана, то для оценки параметров могут использоваться разные методы: Фишера, Юла, Родса, Нейра и др. Сравнительная оценка и обзор этих методов изложены в работе E. М. Четыркина .
Покажем на примере расчет параметров логистической кривой по методу Фишера.
Пример 5.4
Производство продукции характеризуется данными, представленными в табл. 5.4.
Таблица 5.4. Расчет параметров логистической кривой
Метод Фишера основан на определении производной для логистической кривой. Дифференцируя данную функцию по t, получим уравнение
Обозначим темп прироста логистической кривой через . Тогда , т.е. для z,
имеем линейную функцию с параметрами а
и . Чтобы найти решение, необходимо оценить z,. Предполагая, что интервалы между уровнями в ряду динамики равны, Фишер предложил приближенно оценивать в виде уравнения , где п
- 1. Для нашего примера значения z, представлены в графе 3 табл. 5.4. Далее применяем МНК к уравнению: , т.е. строим регрессию z(оту(, беря данные от t = 2 до f = 8. Уравнение регрессии запишется в виде Исходя из него находим параметры а и с для логистической кривой. Параметр а =
0,806. Данное уравнение статистически значимо: F-критерий равен 689,6; R
2 = 0,996. Соответственно для него значимы и параметры: f-критерий для параметра а
равен 47,2 и для параметра – равен -26,2. Так как , то и ![]() т.е. верхняя асимптота производства продукции составляет 403 ед.
т.е. верхняя асимптота производства продукции составляет 403 ед.
После того, как найдены параметры а и с, находим параметр b . Для этого функциюпредставим как Обозначим через Y выражение в левой части равенства, т.е..-Тогда имеем уравнение Прологарифмируем его:. В этом уравнении свободным членом является In Ь. Его можно определить из первого уравнения системы нормальных уравнений, а именно Для нашего примера имеем уравнение . Соответственно Таким образом, логистическая кривая запишется в виде
![]()
Теоретические значения данной функции представлены в графе 6 табл. 5.4 (найдены путем подстановки соответствующих значений t). Они достаточно близко подходят к исходным данным: коэффициент корреляции между ними равен 0,999; ввиду того, что в расчетах использовались логарифмы. Если предположить, что предельное значение объема производства продукции равно 400 ед., т.е. применить МНК к уравнению , то получим и b = =67,5; параметр а при компьютерной обработке определяется как -а = -0,8. Соответственно уравнение тренда запишется в виде . Результаты двух уравнений достаточно близки.
Параметры кривой Гомперца также могут быть оценены МНК, если асимптота с задана, так как в этом случае данная функция сводима к линейному виду Прологарифмировав ее, получим уравнение .
Вторично прологарифмировав, получим уравнение ![]() , Обозначив через у*, lgb через В
и Ig(lga) через А, запишем кривую Гомперца в линейном виде , для оценки параметров которой применим МНК.
, Обозначив через у*, lgb через В
и Ig(lga) через А, запишем кривую Гомперца в линейном виде , для оценки параметров которой применим МНК.
При практическом применении кривой Гомперца могут возникнуть некоторые сложности по динамическому ряду с повышающейся тенденцией. В этом случае задается верхняя асимптота с и логарифмы При повторном логарифмировании в расчетах используются лишь положительные значения Продемонстрируем возможность оценки параметров кривой Гомперца с верхней асимптотой на примере динамики по предприятию товарных запасов на начало каждого месяца (тыс. долл.).
Таблица 5.5. Расчет параметров кривой Гомперца
Когда тип тренда установлен, необходимо вычислить оптимальные значения параметров тренда исходя из фактических уровней. Для этого обычно используют метод наименьших квадратов (МНК). Его значение уже рассмотрено в предыдущих главах учебного пособия, в данном случае оптимизация состоит в минимизации суммы квадратов отклонений фактических уровней ряда от выравненных уровней (от тренда). Для каждого типа тренда МНК дает систему нормальных уравнений, решая которую вычисляют параметры тренда. Рассмотрим лишь три такие системы: для прямой, для параболы 2-го порядка и для экспоненты. Приемы определения параметров других типов тренда рассматриваются в специальной монографической литературе.
Для линейного тренда нормальные уравнения МНК имеют вид:


Нормальные уравнения МНК для экспоненты имеют следующий вид:
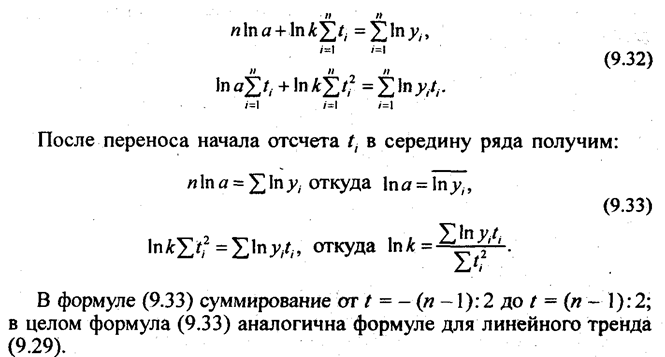
По данным табл. 9.1 рассчитаем все три перечисленных тренда для динамического ряда урожайности картофеля с целью их сравнения (см. табл. 9.5).
Таблица 9.5
Расчет параметров трендов
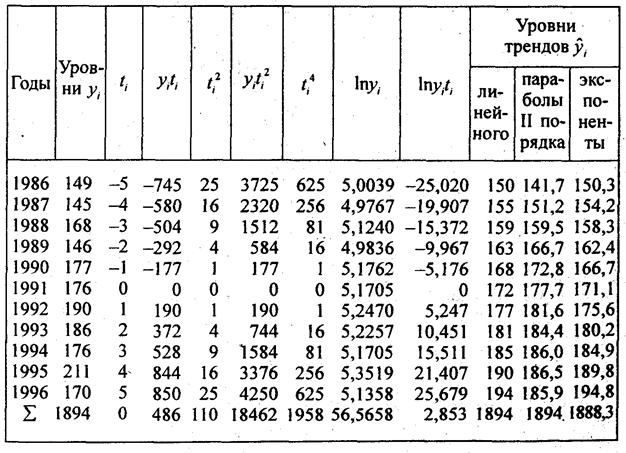
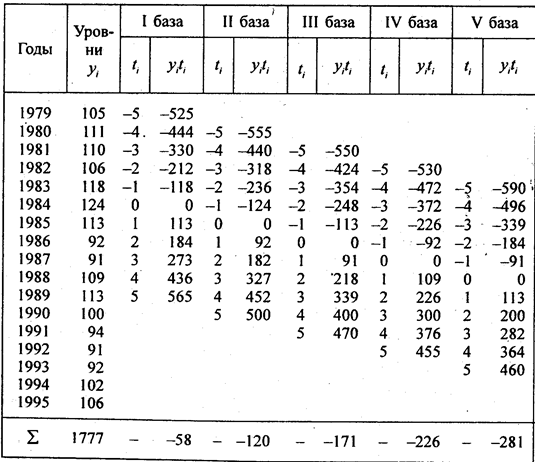
Согласно формуле (9.29) параметры линейного тренда равны а = 1894/11 = 172,2 ц/га; b = 486/110 = 4,418 ц/га. Уравнение линейного тренда имеет вид:
у ̂ = 172,2 + 4,418t , где t = 0 в 1987 г Это означает,что средний фактический и выравненный уровень, отнесенный к середине периода, т.е. к 1991 г., равен 172 ц с 1 ra a среднегодовой прирост составляет 4,418 ц/га в год
Параметры параболического тренда согласно (9.23) равны- b = 4,418; a = 177,75; с = -0,5571. Уравнение параболического тренда имеет вид у̃ = 177,75 + 4,418t - 0.5571t 2 ; t = 0 в 1991 г. Это означает, что абсолютный прирост урожайности замедляется в среднем на 2·0,56 ц/га в год за год. Сам же абсолютный прирост уже не является константой параболического тренда, а является средней величиной за период. В год, принятый за начало отсчета т.е. 1991 г., тренд проходит через точку с ординатой 77,75 ц/га; Свободный член параболического тренда не является средним уровнем за период. Параметры экспоненциального тренда вычисляются по формулам(9.32) и (9.33) lnа = 56,5658/11 = 5,1423; потенцируя, получаем а = 171,1; lnk = 2,853:110 = 0,025936; потенцируя, получаем k = 1,02628.
Уравнение экспоненциального тренда имеет вид: y ̅ = 171,1·1,02628 t .
Это означает, что среднегодовой темп поста урожайности за период составил 102,63%. В точке принятК начало отсчета, тренд проходит точку с ординатой 171,1 ц/га.
Рассчитанные по уравнениям трендов уровни записаны в трех последних графах табл. 9.5. Как видно по этим данным. расчетные значения уровней по всем трем видам трендов различаются ненамного, так как и ускорение параболы, и темп роста экспоненты невелики. Существенное отличие имеет парабола - рост уровней с 1995 г. прекращается, в то время как при линейном тренде уровни растут и далее, а при экспоненте их ост ускоряется. Поэтому для прогнозов на будущее эти три тренда неравноправны: при экстраполяции параболы на будущие годы уровни резко разойдутся с прямой и экспонентой, что видно из табл. 9.6. В этой таблице представлена распечатка решения на ПЭВМ по программе «Statgraphics» тех же трех трендов. Отличие их свободных членов от приведенных выше объясняется тем, что программа нумерует года не от середины, а от начала, так что свободные члены трендов относятся к 1986 г., для которого t = 0. Уравнение экспоненты на распечатке оставлено в логарифмированном виде. Прогноз сделан на 5 лет вперед, т.е. до 2001 г.. При изменении начала координат (отсчета времени) в уравнении параболы меняется и средний абсолютной прирост, параметр b . так как в результате отрицательного ускорения прирост все время сокращается, а его максимум - в начале периода. Константой параболы является только ускорение.
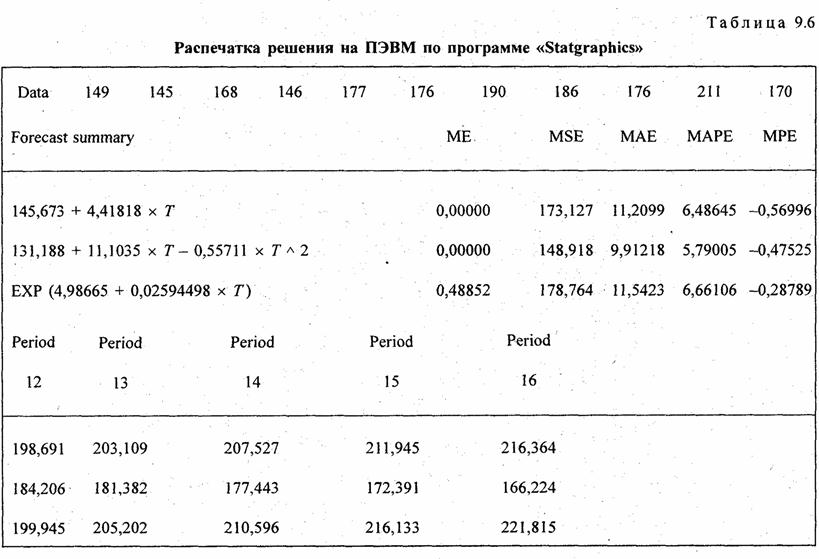
В строке «Data» приводятся уровни исходного ряда; «Forecast summary» означает сводные данные для прогноза. В следующих строках - уравнения прямой, параболы, экспоненты - в логарифмическом виде. Графа ME означает среднее расхождение между уровнями исходного ряда и уровнями тренда (выравненными). Для прямой и параболы это расхождение всегда равно нулю. Уровни экспоненты в среднем на 0,48852 ниже уровней исходного ряда. Точное совпадение возможно, если истинный тренд - экспонента; в данном случае совпадения нет, но различие, мало. Графа МАЕ -это дисперсия s 2 - мера колеблемости фактических уровней относительно тренда, о чем сказано в п. 9.7. Графа МАЕ - среднее линейное отклонение уровней от тренда по модулю (см. параграф 5.8); графа МАРЕ - относительное линейное отклонение в процентах. Здесь они приведены как показатели пригодности выбранного вида тренда. Меньшую дисперсию и модуль отклонения имеет парабола: она за период 1986 - 1996 гг. ближе к фактическим уровням. Но выбор типа тренда нельзя сводить лишь к этому критерию. На самом деле замедление прироста есть результат большого отрицательного отклонения, т. е. неурожая в 1996 г.
Вторая половина таблицы - это прогноз уровней урожайности по трем видам трендов на годы; t = 12, 13, 14, 15 и 16 от начала отсчета (1986 г.). Прогнозируемые уровни по экспоненте вплоть до 16-го года ненамного выше,.чем по прямой. Уровни тренда-параболы - снижаются, все более расходясь с другими трендами.
Как видно в табл. 9.4, при вычислении параметров тренда уровни исходного ряда входят с разными весами - значениями t p и их квадратов. Поэтому влияние колебаний уровней на параметры тренда зависит от того, на какой номер года приходится урожайный либо неурожайный год. Если резкое отклонение приходится на год с нулевым номером (t i = 0 ), то оно никакого влияния на параметры тренда не окажет, а если попадет на начало и конец ряда, то повлияет сильно. Следовательно, однократное аналитическое выравнивание неполно освобождает параметры тренда от влияния колеблемости, и при сильных колебаниях они могут быть сильно искажены, что в нашем примере случилось с параболой. Для дальнейшего исключения искажающего влияния колебаний на параметры тренда следует применить метод многократного скользящего выравнивания.
Этот прием состоит в том, что параметры тренда вычисляются не сразу по всему ряду, а скользящим методом, сначала за первые т периодов времени или моментов, затем за период от 2-го до т + 1, от 3-го до (т + 2)-го уровня и т.п. Если число исходных уровней ряда равно п, а длина каждой скользящей базы расчета параметров равна т, то число таких скользящих баз t или отдельных значений параметров, которые будут по ним определены, составит:
L = п + 1 - т.
Применение методики скользящего многократного выравнивания рассматривать, как видно из приведенных расчетов, возможно только при достаточно большом числе уровней ряда, как правило 15 и более. Рассмотрим эту методику на примере данных табл. 9.4 -динамики цен на нетопливные товары развивающихся стран, что опять же дает возможность читателю участвовать в небольшом научном исследовании. На этом же примере продолжим и методику прогнозирования в разделе 9.10.
Если вычислять в нашем ряду параметры по 11 -летним периодам (по 11 уровням), то t = 17 + 1 - 11 = 7. Смысл многократного скользящего выравнивания в том, что при последовательных сдвигах базы расчета параметров на концах ее и в середине окажутся разные уровни с разными по знаку и величине отклонениями от тренда. Поэтому при одних сдвигах базы параметры будут завышаться, при других - занижаться, а при последующем усреднении значений параметров по всем сдвигам базы расчета произойдет дальнейшее взаимопогашение искажений параметров тренда колебаниями уровней.
Многократное скользящее выравнивание не только позволяет получить более точную и надежную оценку параметров тренда, но и осуществить контроль правильности выбора типа уравнения тренда. Если окажется, что ведущий параметр тренда, его константа при расчете по скользящим базам не беспорядочно колеблется, а систематически изменяет свою величину существенным образом, значит, тип тренда был выбран неверно, данный параметр константой не является.
Что касается свободного члена при многократном выравнивании, то нет необходимости и, более того, просто неверно вычислять его величину как среднюю по всем сдвигам базы, ибо при таком способе отдельные уровни исходного ряда входили бы в расчет средней с разными весами, и сумма выравненных уровней разошлась бы с суммой членов исходного ряда. Свободный член тренда - это средняя величина уровня за период, при условии отсчета времени от середины периода. При отсчете от начала, если первый уровень t i = 1, свободный член будет равен: a 0 = у ̅ - b ((N-1)/2). Рекомендуется длину скользящей базы расчета параметров тренда выбирать не менее 9-11 уровней, чтобы в достаточной мере погасить колебания уровней. Если исходный ряд очень длинный, база может составлять до 0,7 - 0,8 его длины. Для устранения влияния долго-периодических (циклических) колебаний на параметры тренда, число сдвигов базы должно быть равно или кратно длине цикла колебаний. Тогда начало и конец базы будут последовательно «пробегать» все фазы цикла и при усреднении параметра по всем сдвигам его искажения от циклических колебаний будут взаимопогашаться. Другой способ - взять длину скользящей базы, равной длине цикла, чтобы начало базы и конец базы всегда приходились на одну и ту же фазу цикла колебаний.
Поскольку по данным табл. 9.4, уже было установлено, что тренд имеет линейную форму, проводим расчет среднегодового абсолютного прироста, т. е. параметра b уравнения линейного тренда скользящим способом по 11-летним базам (см. табл. 9.7). В ней же приведен расчет данных, необходимых для последующего изучения колеблемости в параграфе 9.7. Остановимся подробнее на методике многократного выравнивания по скользящим базам. Рассчитаем параметр b по всем базам:
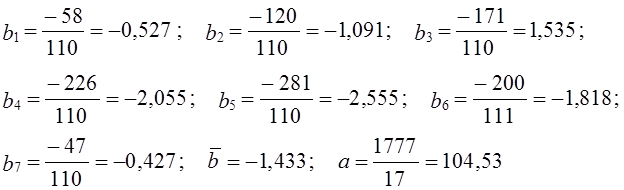
Таблица 9.7
Многократное скользящее выравнивание по прямой
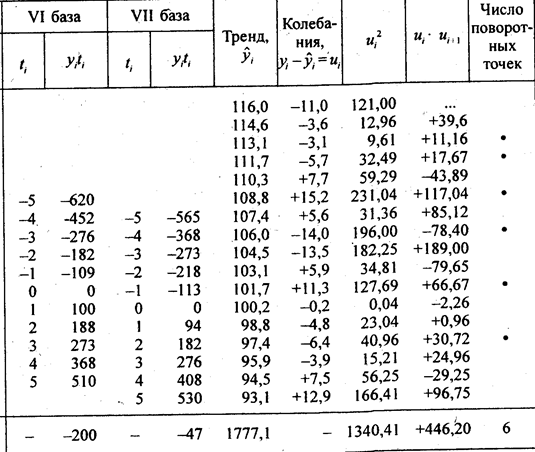
Уравнение тренда: у ̂ = 104,53 - 1,433t ; t = 0 в 1987 г. Итак, индекс цен в среднем за год снижался на 1,433 пункта. Однократное выравнивание по всем 17 уровням может исказить этот параметр, ибо начальный уровень содержит значительное отрицательное отклонение, а конечный уровень - положительное. В самом деле, однократное выравнивание дает величину среднегодового изменения индекса всего на 0,953 пункта.
9.7. Методика изучения и показатели колеблемости
Если при изучении и измерении тенденции динамики колебания уровней играли лишь роль помех, «информационного шума», от которого следовало по возможности абстрагироваться, то в дальнейшем сама колеблемость становится предметом статистического исследования. Значение изучения колебаний уровней динамического ряда очевидно: колебания урожайности, продуктивности скота, производства мяса экономически нежелательны, так как потребность в продукции агрокомплекса постоянна. Эти колебания следует уменьшать, применяя прогрессивную технологию и другие меры. Напротив, сезонные колебания объемов производства зимней и летней обуви, одежды, мороженого, зонтиков, коньков - необходимы и закономерны, так как спрос на эти товары тоже колеблется по сезонам и равномерное производство требует лишних затрат на хранение запасов. Регулирование рыночной экономики как со стороны государства, так и производителей в значительной мере состоит в регулировании колебаний экономических процессов.
Типы колебаний статистических показателей весьма разнообразны, но все же можно выделить три основных: пилообразную или маятниковую колеблемость, циклическую долгопериодическую и случайно распределенную во времени колеблемость. Их свойства и отличия друг от друга хорошо видны при графическом изображении рис. 9.2.
Пилообразная или маятниковая колеблемость состоит в попеременных отклонениях уровней от тренда в одну и в другую сторону. Таковы автоколебания маятника. Такие автоколебания можно наблюдать в динамике урожайности при невысоком уровне агротехники: высокий урожай при благоприятных условиях погоды выносит из почвы больше питательных веществ, чем их образуется естественным путем за год; почва обедняется, что вызывает снижение следу- ющего урожая ниже тренда, он выносит меньше питательных веществ, чем образуется за год, плодородие возрастает и т.д.

Рис. 9.2. Виды колебаний
Циклическая долгопериодическая колеблемость свойственна, например, солнечной активности (10-11-летние циклы), а значит, и связанным с ней на Земле процессам - полярным сияниям, грозовой деятельности, урожайности отдельных культур в ряде районов, некоторым заболеваниям людей, растений. Для этого типа характерны редкая смена знаков отклонений от тренда и кумулятивный (накапливающийся) эффект отклонений одного знака, который может тяжело отражаться на экономике. Зато колебания хорошо прогнозируются.
Случайно распределенная во времени колеблемость - нерегулярная, хаотическая. Она может возникать при наложении (интерференции) множества колебаний с разными по длительности циклами. Но может возникать в результате столь же хаотической колеблемости главной причины существования колебаний, например суммы осадков за летний период, температуры воздуха в среднем за месяц в разные годы.
Для определения типа колебаний применяются графическое изображение, метод «поворотных точек» М. Кендэла, вычисление коэффициентов автокорреляции отклонений от тренда. Эти методы будут рассмотрены далее.
Основными показателями, характеризующими силу колеблемости уровней, выступают уже известные по главе 5 показатели, характеризующие вариацию значений признака в пространственной совокупности. Однако вариация в пространстве и колеблемость во времени принципиально различны. Прежде всего различны их основные причины. Вариация значений признака у одновременно существующих единиц возникает из-за различий в условиях существования единиц совокупности. Например, разная урожайность картофеля в совхозах области в 1990 г. вызвана различиями в плодородии почв, в качестве семян, в агротехнике. А вот суммы эффективных температур за вегетационный период и осадков не являются причинами пространственной вариации, так как в одном и том же году на территории области эти факторы почти не варьируют. Напротив, главными причинами колебания урожайности картофеля в области за ряд лет как раз являются колебания метеорологических факторов, а качество почв колебаний почти не имеет. Что же касается общего прогресса агротехники, то он является причиной тренда, но не колеблемости.
Второе коренное отличие состоит в том, что значения варьирующего признака в пространственной совокупности можно считать в основном не зависимыми друг от друга, напротив, уровни динамического ряда, как правило, являются зависимыми: это показатели развивающегося процесса, каждая стадия которого связана с предыдущими состояниями.
В-третьих, вариация в пространственной совокупности измеряется отклонениями индивидуальных значений признака от среднего значения, а колеблемость уровней динамического ряда измеряется не их отличиями от среднего уровня (эти отличия включают и тренд, и колебания), а отклонениями уровней от тренда.
Поэтому лучше использовать разные термины: различия признака в пространственной совокупности называть только вариацией, но не колебаниями: никто же не станет называть различия численности населения Москвы, Петербурга, Киева и Ташкента «колебаниями числа жителей»! Отклонения уровней динамического ряда от тренда будем называть всегда колеблемостью. Колебания всегда происходят во времени, не может существовать колебаний вне времени, в фиксированный момент.
На основе качественного содержания понятия колеблемости строится и система ее показателей. Показателями силы колебании уровней являются: амплитуда отклонений уровней отдельных периодов или моментов от тренда (по модулю), среднее абсолютное отклонение уровней от тренда (по модулю), среднее квадратическое откло;-нение уровней от тренда. Относительные меры колеблемости: относительное линейное отклонение от тренда и коэффициент колеблемости - аналог коэффициента вариации.
Особенностью методики вычисления средних отклонений от тренда является необходимость учета потерь степеней свободы колебаний на величину, равную числу параметров уравнения тренда. Например, прямая линия имеет два параметра, и, как известно из геометрии, через любые две точки можно провести прямую линию. Значит, имея лишь два уровня, мы проведем линию тренда точно через эти два уровня, и никаких отклонений уровней от тренда не окажется, хотя на самом деле и эти два уровня включали колебания, не были свободны от действия факторов колеблемости. Парабола второго порядка пройдет точно через любые три точки и т.п.
Учитывая потерю степеней свободы, основные абсолютные показатели колеблемости вычисляются по формулам (9.34) и (9.35):
среднее линейное отклонение
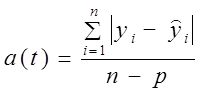 (9.34)
(9.34)
среднее квадратичное отклонение
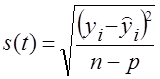 (9.35)
(9.35)
где y i - фактический уровень;
y ̂ i - выравненный уровень, тренд;
n - число уровней;
р - число параметров тренда.
Знак времени «t » в скобках после показателя означает, что это показатель не обычной пространственной вариации, как в главе V, а показатель колеблемости во времени.
Относительные показатели колеблемости вычисляются делением абсолютных показателей на средний уровень за весь изучаемый период. Расчет показателей колеблемости проведем по результатам анализа динамики индекса цен (см. табл. 9.7). Тренд примем по результатам многократного скользящего выравнивания, т. е. у ̂ = 104,53 - 1,433t ; t = 0 в 1987 г.
1. Амплитуда колебаний составила от -14,0 в 1986 г. до +15,2 в 1984 г., т.е. 29,2 пункта.
2. Среднее линейное отклонение по модулю найдем, сложив модули |u i | (их сумма равна 132,3), и разделив на (п - р), согласно формуле (9.34):
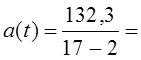 =8,82 пункта.
=8,82 пункта.
3. Среднее квадратическое отклонение уровней от тренда по формуле (9.35) составило:
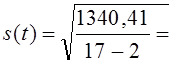 = 9,45 пункта.
= 9,45 пункта.
Небольшое превышение среднего квадратического отклонения над линейным указывает на отсутствие среди отклонений резко выделяющихся по абсолютной величине.
4. Коэффициент колеблемости: 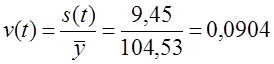 или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда:
или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда:
s (t ) = 14,38 ц с 1 га, v (t ) = 8,35%.
Для выявления типа колебаний воспользуемся приемом, предложенным М. Кендэлом. Он состоит в подсчете так называемых «поворотных точек» в ряду отклонений от тренда и i т. е. локальных экстремумов. Отклонение, либо большее по алгебраической величине, либо меньшее двух соседних, отмечается точкой. Обратимся к рис. 9.2. При маятниковой колеблемости все отклонения, кроме двух крайних, будут «поворотными», следовательно, их число составит п - 1. При долгопериодических циклах на цикл приходятся один минимум и один максимум, а общее число точек составит 2(n : l ), где l - длительность цикла. При случайно распределенной во времени колеблемости, как доказал М. Кендэл, число поворотных точек в среднем составит: 2/3 (n - 2). В нашем примере при маятниковой колеблемости было бы 15 точек, при связанной с 11-летним циклом было бы 2-(17: 11) ≈ 3 точки, при случайно распределенной во времени в среднем было бы (2/3)·(17-2) =10 точек.
Фактическое число точек 6 выходит за границы двукратного среднего квадратического отклонения числа поворотных точек, которое по Кендэлу равно , в нашем случае 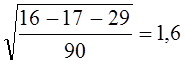 .
.
Наличие 6 точек, при 2 точках за цикл, означает, что в ряду могут быть примерно 3 цикла, продолжительность периода которых 5,5 - 6 лет. Возможно сочетание таких циклических колебаний со случайными.
Другой метод анализа типа колеблемости и поиска длины цикла основан на вычислении коэффициентов автокорреляции отклонений от тренда.
Автокорреляция - это корреляция между уровнями ряда или отклонениями от тренда, взятыми со сдвигом во времени: на 1 период (год), на 2, на 3 и т. д., поэтому говорят о коэффициентах автокорреляции разных порядков: первого, второго и т. д. Рассмотрим сначала коэффициент автокорреляции отклонений от тренда первого порядка.
Одна из основных формул для расчета коэффициента автокорреляции отклонений от тренда имеет вид:
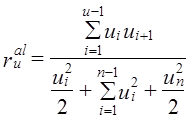 (9.36)
(9.36)
Как легко видеть по табл. 9.7, первое и последнее в ряду отклонения участвуют только в одном произведении в числителе, а все прочие отклонения от второго до (п - 1)-го - в двух. Поэтому и в знаменателе квадраты первого и последнего отклонений следует взять с половинным весом, как в хронологической средней. По данным табл. 9.7 имеем:
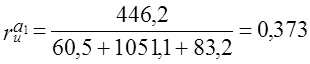
Теперь обратимся к рис. 9.2. При маятниковой колеблемости все произведения в числителе будут отрицательными величинами, и коэффициент автокорреляции первого порядка будет близок к -1. При долголериодических циклах будут преобладать положительные произведения соседних отклонений, а смена знака происходит лишь дважды за цикл. Чем длиннее Цикл, тем больше перевес положительных произведений в числителе, и коэффициент автокорреляции первого порядка ближе к +1. При случайно распределенной во времени колеблемости знаки отклонений чередуются хаотически, число положительных произведений близко к числу отрицательных, ввиду чего коэффициент автокорреляции близок к нулю. Полученное значение говорит о наличии как случайно распределенных во времени колебаний, так и циклических. Коэффициенты автокорреляции следующих порядков: II = - 0,577; Ш = -0,611; IV == -0,095; V = +0,376; VI = +0,404; VII = +0,044. Следовательно, противофаза цикла ближе всего кЗ годам (наибольший отрицательный коэффициент при сдвиге на 3 года), а совпадающие фазы ближе к б годам, что и дает длину цикла колебаний. Эти максимальные по абсолютной величине коэффициенты не близки к единице. Это означает, что циклическая колеблемость смешана со значительной случайной колеблемостью. Таким образом, подробный автокорреляционный анализ в целом дал те же результаты, что и выводы по автокорреляции первого порядка.
Если динамический ряд достаточно длинен, можно поставить и решить задачу об изменении показателей колеблемости с течением времени. Для этого рассчитывают эти показатели по подпериодам, но длительностью не менее 9-11 лет, иначе измерения колеблемости ненадежны. Кроме того, можно рассчитывать показатели колеблемости скользящим способом, а затем произвести их выравнивание, т. е. вычислить тренд показателей колеблемости. Это полезно, чтобы сделать вывод о действенности мер, применявшихся для уменьшения колебаний урожайности и других нежелательных колебаний, а также для того, чтобы по тренду сделать прогноз ожидаемых в будущем размеров колебаний.
9.8. Измерение устойчивости в динамике
Понятие «устойчивость» используется в весьма различных смыслах. По отношению к статистическому изучению динамики мы рассмотрим два аспекта этого понятия: 1) устойчивость как категория, противоположная колеблемости; 2) устойчивость направленности изменений, т. е. устойчивость тенденции.
В первом понимании показатель устойчивости, который может быть только относительным, должен изменяться от нуля до единицы (100%). Это разность между единицей и относительным показателем колеблемости. Коэффициент колеблемости составил 9,0%. Следовательно, коэффициент устойчивости равен 100% - 9,0% = 91,0%. Этот показатель характеризует близость фактических уровней к тренду и совершенно не зависит от характера последнего. Слабая колеблемость и высокая устойчивость уровней в данном смысле могут существовать даже при полном застое в развитии, когда тренд выражен горизонтальной прямой.
Устойчивость во втором смысле характеризует не сами по себе уровни, а процесс их направленного изменения. Можно узнать, например, насколько устойчив процесс сокращения удельных затрат ресурсов на производство единицы продукции, является ли устойчивой тенденция снижения детской смертности и т. д. С этой точки зрения полной устойчивостью направленного изменения уровней динамического ряда следует считать такое изменение, в процессе которого каждый следующий уровень либо выше всех предшествующих (устойчивый рост), либо ниже всех предшествующих (устойчивое снижение). Всякое нарушение строго ранжированной последовательности уровней свидетельствует о неполной устойчивости изменений.
Из определения понятия устойчивости тенденции вытекает и метод построения ее показателя. В качестве показателя устойчивости можно использовать коэффициент корреляции рангов Ч. Спирмэна (Spearman) - r x .
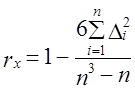
где п - число уровней;
Δ i - разность рангов уровней и номеров периодов времени.
При полном совпадении рангов уровней, начиная с наименьшего, и номеров периодов (моментов) времени по их хронологическому порядку коэффициент корреляции рангов равен +1. Это значение соответствует случаю полной устойчивости возрастания уровней. При полной противоположности рангов уровней рангам лет коэффициент Спирмэна равен -1, что означает полную устойчивость процесса сокращения уровней. При хаотическом чередовании рангов уровней коэффициент близок к нулю, это означает неустойчивость какой-либо тенденции. Приведем расчет коэффициента корреляции Спирмэна по данным о динамике индекса цен (табл. 9.7) в табл. 9.8.
Таблица 9.8
Расчет коэффициентов корреляции рангов Спирмена
|
Ранг лет, Р x |
Ранг уровней, Р у |
Р x -Р y |
(P x -P y ) 2 |
||
Ввиду наличия трех пар «связанных рангов» применяем формулу (8.26):
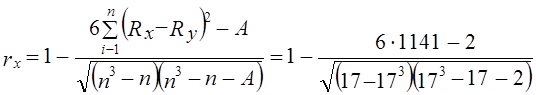
Отрицательное значение r x указывает на наличие тенденции снижения уровней, причем устойчивость этой тенденции ниже средней.
При этом следует иметь в виду, что даже при 100%-ной устойчивости тенденции в ряду динамики может быть колеблемость уровней, и коэффициент их устойчивости будет ниже 100%. При слабой колеблемости, но еще более слабой тенденции, напротив, возможен высокий коэффициент устойчивости уровней, но близкий к нулю коэффициент устойчивости тренда. В целом же оба показателя связаны, конечно, прямой зависимостью: чаще всего большая устойчивость уровней наблюдается одновременно с большей устойчивостью тренда.
Устойчивость тенденции развития или комплексная устойчивость, в динамике может быть охарактеризована соотношением между среднегодовым абсолютным изменением и средним квадратическим (либо линейным) отклонением уровней от тренда:
Если, как нередко бывает, распределение отклонений уровней ряда от тренда близко к нормальному, то с вероятностью 0,95 отклонение от тренда вниз не превысит 1,645s (t ) по величине. Следовательно, если в ряду динамики
с > 1,64, то уровни, более низкие, чем предыдущие, в среднем будут встречаться менее 5раз за 100 периодов, или 1 раз из 20, т. е. устойчивость тренда будет высока. При с = 1 нарушения ранжированности уровней будут встречаться в среднем 16 раз из 100, а при с = 0,5 – уже 31 раз из 100, т. е. устойчивость тенденции будет низкой. Можно также пользоваться отношением среднего темпа прироста к коэффициенту колеблемости, что дает показатель, близкий к с - показателю устойчивости. Этот показатель более пригоден для экспоненциального тренда. О показателях устойчивости нелинейных трендов и об общих проблемах устойчивости экономических и социальных процессов можно подробнее прочесть в рекомендуемой к данной главе литературе .
Назначение сервиса . Сервис используется для расчета параметров тренда временного ряда y t онлайн с помощью метода наименьших квадратов (МНК) (см. пример нахождения уравнения тренда), а также способом от условного нуля. Для этого строится система уравнений:a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
и таблица следующего вида:
| t | y | t 2 | y 2 | t y | y(t) |
| 1 | |||||
| ... | ... | ... | ... | ... | ... |
| N | |||||
| ИТОГО | ∑ | ∑ | ∑ | ∑ | ∑ |
Инструкция . Укажите количество данных (количество строк). Полученное решение сохраняется в файле Word и Excel .
Тенденция временного ряда характеризует совокупность факторов, оказывающих долговременное влияние и формирующих общую динамику изучаемого показателя.
Способ отсчета времени от условного начала
Для определения параметров математической функции при анализе тренда в рядах динамики используется способ отсчета времени от условного начала. Он основан на обозначении в ряду динамики показаний времени таким образом, чтобы ∑t i . При этом в ряду динамики с нечетным числом уровней порядковый номер уровня, находящегося в середине ряда, обозначают через нулевое значение и принимают его за условное начало отсчета времени с интервалом +1 всех последующих уровней и –1 всех предыдущих уровней. Например, при обозначения времени будут: –2, –1, 0, +1, +2 . При четном числе уровней порядковые номера верхней половины ряда (от середины) обозначаются числами: –1, –3, –5 , а нижней половины ряда обозначаются +1, +3, +5 .Пример . Статистическое изучение динамики численности населения.
- С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
- С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
- Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
| 1990 | 1996 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
| 1249 | 1133 | 1043 | 1030 | 1016 | 1005 | 996 | 985 | 975 | 968 |
а) Линейное уравнение тренда имеет вид y = bt + a
1. Находим параметры уравнения методом наименьших квадратов
. Используем способ отсчета времени от условного начала.
Система уравнений МНК для линейного тренда имеет вид:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y |
| -9 | 1249 | 81 | 1560001 | -11241 |
| -7 | 1133 | 49 | 1283689 | -7931 |
| -5 | 1043 | 25 | 1087849 | -5215 |
| -3 | 1030 | 9 | 1060900 | -3090 |
| -1 | 1016 | 1 | 1032256 | -1016 |
| 1 | 1005 | 1 | 1010025 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 |
| 5 | 985 | 25 | 970225 | 4925 |
| 7 | 975 | 49 | 950625 | 6825 |
| 9 | 968 | 81 | 937024 | 8712 |
| 0 | 10400 | 330 | 10884610 | -4038 |
Для наших данных система уравнений примет вид:
10a 0 + 0a 1 = 10400
0a 0 + 330a 1 = -4038
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = -12.236, a 1 = 1040
Уравнение тренда:
y = -12.236 t + 1040
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе уравнения тренда к исходным данным.
![]()
б) выравнивание по параболе
Уравнение тренда имеет вид y = at 2 + bt + c
1. Находим параметры уравнения методом наименьших квадратов.
Система уравнений МНК:
a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y
a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt
a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
| t | y | t 2 | y 2 | t y | t 3 | t 4 | t 2 y |
| -9 | 1249 | 81 | 1560001 | -11241 | -729 | 6561 | 101169 |
| -7 | 1133 | 49 | 1283689 | -7931 | -343 | 2401 | 55517 |
| -5 | 1043 | 25 | 1087849 | -5215 | -125 | 625 | 26075 |
| -3 | 1030 | 9 | 1060900 | -3090 | -27 | 81 | 9270 |
| -1 | 1016 | 1 | 1032256 | -1016 | -1 | 1 | 1016 |
| 1 | 1005 | 1 | 1010025 | 1005 | 1 | 1 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 | 27 | 81 | 8964 |
| 5 | 985 | 25 | 970225 | 4925 | 125 | 625 | 24625 |
| 7 | 975 | 49 | 950625 | 6825 | 343 | 2401 | 47775 |
| 9 | 968 | 81 | 937024 | 8712 | 729 | 6561 | 78408 |
| 0 | 10400 | 330 | 10884610 | -4038 | 0 | 19338 | 353824 |
Для наших данных система уравнений имеет вид
10a 0 + 0a 1 + 330a 2 = 10400
0a 0 + 330a 1 + 0a 2 = -4038
330a 0 + 0a 1 + 19338a 2 = 353824
Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5
Уравнение тренда:
y = 1.258t 2 -12.236t+998.5
Ошибка аппроксимации для параболического уравнения тренда.
![]()
Поскольку ошибка меньше 7%, то данное уравнение можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный прогноз.
Определим среднеквадратическую ошибку прогнозируемого показателя.

m = 1 - количество влияющих факторов в уравнении тренда.
Uy = y n+L ± K
где

L - период упреждения; у n+L - точечный прогноз по модели на (n + L)-й момент времени; n - количество наблюдений во временном ряду; Sy - стандартная ошибка прогнозируемого показателя; T табл - табличное значение критерия Стьюдента для уровня значимости α и для числа степеней свободы, равного n-2
.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (8;0.025) = 2.306
Точечный прогноз, t = 10: y(10) = 1.26*10 2 -12.24*10 + 998.5 = 1001.89 тыс. чел.
1001.89 - 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный прогноз:
t = 9+1 = 10: (930.76;1073.02)
ПРИМЕР . Статистическое изучение динамики численности населения.
С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
Метод аналитического выравнивания а) Линейное уравнение тренда имеет вид y = bt + a 1. Находим параметры уравнения методом наименьших квадратов . Используем способ отсчета времени от условного начала. Система уравнений МНК для линейного тренда имеет вид: a 0 n + a 1 ∑t = ∑y a 0 ∑t + a 1 ∑t 2 = ∑y t
Для наших данных система уравнений примет вид: 10a 0 + 0a 1 = 10400 0a 0 + 330a 1 = -4038 Из первого уравнения выражаем а 0 и подставим во второе уравнение Получаем a 0 = -12.236, a 1 = 1040 Уравнение тренда: y = -12.236 t + 1040
Оценим
качество уравнения тренда с помощью
ошибки абсолютной аппроксимации.
Ошибка
аппроксимации в пределах 5%-7% свидетельствует
о хорошем подборе уравнения тренда к
исходным данным.![]()
б) выравнивание по параболе Уравнение тренда имеет вид y = at 2 + bt + c 1. Находим параметры уравнения методом наименьших квадратов. Система уравнений МНК: a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
Для наших данных система уравнений имеет вид 10a 0 + 0a 1 + 330a 2 = 10400 0a 0 + 330a 1 + 0a 2 = -4038 330a 0 + 0a 1 + 19338a 2 = 353824 Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5 Уравнение тренда: y = 1.258t 2 -12.236t+998.5
Ошибка
аппроксимации для параболического
уравнения тренда.
![]() Поскольку
ошибка меньше 7%, то данное уравнение
можно использовать в качестве тренда.
Поскольку
ошибка меньше 7%, то данное уравнение
можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный
прогноз.
Определим среднеквадратическую
ошибку прогнозируемого показателя.
![]() m
= 1 - количество влияющих факторов в
уравнении тренда.
Uy = y n+L ±
K
где
m
= 1 - количество влияющих факторов в
уравнении тренда.
Uy = y n+L ±
K
где
![]() L
- период упреждения; у n+L -
точечный прогноз по модели на (n + L)-й
момент времени; n - количество наблюдений
во временном ряду; Sy - стандартная ошибка
прогнозируемого показателя; T табл -
табличное значение критерия Стьюдента
для уровня значимости α и для числа
степеней свободы, равного n-2
.
По
таблице Стьюдента находим
Tтабл
T табл (n-m-1;α/2)
= (8;0.025) = 2.306
Точечный прогноз, t = 10:
y(10) = 1.26*10 2 -12.24*10
+ 998.5 = 1001.89 тыс. чел.
1001.89
- 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный
прогноз:
t = 9+1 = 10: (930.76;1073.02)
L
- период упреждения; у n+L -
точечный прогноз по модели на (n + L)-й
момент времени; n - количество наблюдений
во временном ряду; Sy - стандартная ошибка
прогнозируемого показателя; T табл -
табличное значение критерия Стьюдента
для уровня значимости α и для числа
степеней свободы, равного n-2
.
По
таблице Стьюдента находим
Tтабл
T табл (n-m-1;α/2)
= (8;0.025) = 2.306
Точечный прогноз, t = 10:
y(10) = 1.26*10 2 -12.24*10
+ 998.5 = 1001.89 тыс. чел.
1001.89
- 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный
прогноз:
t = 9+1 = 10: (930.76;1073.02)




