Критерий пирсона хи квадрат закон распределения матлаб. Сравнение двух частотных распределений
23. Понятие распределения хи-квадрат и Стьюдента, и графический вид
1) Распределение (хи-квадрат) с n степенями свободы - это распределение суммы квадратов n независимых стандартных нормальных случайных величин.
Распределение (хи – квадрат) – распределение случайной величины (причем математическое ожидание каждой из них равно 0, а среднее квадратическое отклонение-1)
где
случайные величины
![]() независимы
и имеют одно и тоже распределение.
При этом число слагаемых, т.е.,
называется "числом степеней свободы"
распределения хи-квадрат. Число хи-квадрат
опредляется одни параметром-числом
степеней свободы. С увеличением числа
степеней свободы распределение медленно
приближается к нормальному.
независимы
и имеют одно и тоже распределение.
При этом число слагаемых, т.е.,
называется "числом степеней свободы"
распределения хи-квадрат. Число хи-квадрат
опредляется одни параметром-числом
степеней свободы. С увеличением числа
степеней свободы распределение медленно
приближается к нормальному.
Тогда сумма их квадратов
является случайной величиной, распределенной по так называемому закону «хи-квадрат» с k = n степенями свободы; если же слагаемые связаны каким-либо соотношением (например, ), то число степеней свободы k = n – 1.
Плотность этого распределения

Здесь
![]() - гамма-функция; в частности, Г(п + 1) = п!
.
- гамма-функция; в частности, Г(п + 1) = п!
.
Следовательно, распределение «хи-квадрат» определяется одним параметром – числом степеней свободы k.
Замечание 1. С увеличением числа степеней свободы распределение «хи-квадрат» постепенно приближается к нормальному.
Замечание 2. С помощью распределения «хи-квадрат» определяются многие другие распреде-ления, встречающиеся на практике, например, распределение случайной величины - длины случайного вектора (Х1, Х2,…, Хп), координаты которого независимы и распределены по нормальному закону.
Впервые χ2-распределение было рассмотрено Р.Хельмертом (1876) и К.Пирсоном (1900).
Мат.ожид.=n; D=2n

2) Распределение Стьюдента
Рассмотрим две независимые случайные величины: Z, имеющую нормальное распределение и нормированную (то есть М(Z) = 0, σ(Z) = 1), и V, распределенную по закону «хи-квадрат» с k степенями свободы. Тогда величина
имеет распределение, называемое t – распределением или распределением Стьюдента с k степенями свободы. При этом k называется "числом степеней свободы" распределения Стьюдента.
С возрастанием числа степеней свободы распределение Стьюдента быстро приближается к нормальному.
Это распределение было введено в 1908 г. английским статистиком В. Госсетом, работавшем на фабрике, выпускающей пиво. Вероятностно-статистические методы использовались для принятия экономических и технических решений на этой фабрике, поэтому ее руководство запрещало В. Госсету публиковать научные статьи под своим именем. Таким способом охранялась коммерческая тайна, "ноу-хау" в виде вероятностно-статистических методов, разработанных В. Госсетом. Однако он имел возможность публиковаться под псевдонимом "Стьюдент". История Госсета – Стьюдента показывает, что еще сто лет назад менеджерам Великобритании была очевидна большая экономическая эффективность вероятностно-статистических методов принятия решений.

Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F(x) и эмпирическим распределением F* п (x) , которая приближенно подчиняется закону распределения χ 2 . Гипотеза Н 0 о согласованности распределений проверяется путем анализа распределения этой статистики. Применение критерия требует построения статистического ряда.
Итак, пусть выборка представлена статистическим рядом с количеством разрядов M . Наблюдаемая частота попаданий в i- й разряд n i . В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i -й разряд составляет F i . Разность между наблюдаемой и ожидаемой частотой составит величину (n i – F i ). Для нахождения общей степени расхождения между F(x ) и F* п (x ) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда
Величина χ 2 при неограниченном увеличении n имеет χ 2 -распределение (асимптотически распределена как χ 2). Это распределение зависит от числа степеней свободы k , т.е. количества независимых значений слагаемых в выражении (3.7). Число степеней свободы равно числу y минус число линейных связей, наложенных на выборку. Одна связь существует в силу того, что любая частота может быть вычислена по совокупности частот в оставшихся M –1 разрядах. Кроме того, если параметры распределения неизвестны заранее, то имеется еще одно ограничение, обусловленное подгонкой распределения к выборке. Если по выборке определяются S параметров распределения, то число степеней свободы составит k=M –S–1.
Область принятия гипотезы Н 0 определяется условием χ 2 < χ 2 (k;a) , где χ 2 (k;a) – критическая точка χ2-распределения с уровнем значимости a . Вероятность ошибки первого рода равна a , вероятность ошибки второго рода четко определить нельзя, потому что существует бесконечно большое множество различных способов несовпадения распределений. Мощность критерия зависит от количества разрядов и объема выборки. Критерий рекомендуется применять при n >200, допускается применение при n >40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Алгоритм проверки по критерию
1. Построить гистограмму равновероятностным способом.
2. По виду гистограммы выдвинуть гипотезу
H 0: f (x ) = f 0(x ),
H 1: f (x ) f 0(x ),
где f 0(x ) - плотность вероятности гипотетического закона распределения (например, равномерного, экспоненциального, нормального).
Замечание . Гипотезу об экспоненциальном законе распределения можно выдвигать в том случае, если все числа в выборке положительные.
3. Вычислить значение критерия по формуле
 ,
,
где частота попадания в i -тый интервал;
pi - теоретическая вероятность попадания случайной величины в i - тый интервал при условии, что гипотеза H 0верна.
Формулы для расчета pi в случае экспоненциального, равномерного и нормального законов соответственно равны.
Экспоненциальный закон
![]() . (3.8)
. (3.8)
При этом A 1 = 0, Bm = +.
Равномерный закон
Нормальный закон
 . (3.10)
. (3.10)
При этом A 1 = -, B M = +.
Замечания . После вычисления всех вероятностей pi проверить, выполняется ли контрольное соотношение

Функция Ф(х )- нечетная. Ф(+) = 1.
4. Из таблицы " Хи-квадрат" Приложения выбирается значение , где - заданный уровень значимости (= 0,05 или = 0,01), а k - число степеней свободы, определяемое по формуле
k = M - 1 - S .
Здесь S - число параметров, от которых зависит выбранный гипотезой H 0закон распределения. Значения S для равномерного закона равно 2, для экспоненциального - 1, для нормального - 2.
5. Если , то гипотеза H 0отклоняется. В противном случае нет оснований ее отклонить: с вероятностью 1 - она верна, а с вероятностью - неверна, но величина неизвестна.
Пример3 . 1. С помощью критерия 2выдвинуть и проверить гипотезу о законе распределения случайной величины X , вариационный ряд, интервальные таблицы и гистограммы распределения которой приведены в примере 1.2. Уровень значимости равен 0,05.
Решение . По виду гистограмм выдвигаем гипотезу о том, что случайная величина X распределена по нормальному закону:
H 0: f (x ) = N (m ,);
H 1: f (x ) N (m ,).
Значение критерия вычисляем по формуле.
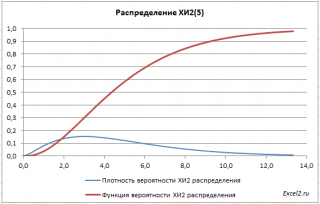
Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL ХИ2.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат (Х 2 , ХИ2, англ. Chi - squared distribution ) применяется в различных методах математической статистики:
- при построении ;
- при ;
- при (согласуются ли эмпирические данные с нашим предположением о теоретической функции распределения или нет, англ. Goodness-of-fit)
- при (используется для определения связи между двумя категориальными переменными, англ. Chi-square test of association).
Определение : Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1 2 + x 2 2 +…+ x n 2 имеет распределение Х 2 с n степенями свободы.
Распределение Х 2 зависит от одного параметра, который называется степенью свободы (df , degrees of freedom ). Например, при построении число степеней свободы равно df=n-1, где n – размер выборки .
Плотность распределения
Х 2
выражается формулой:
Графики функций
Распределение Х 2 имеет несимметричную форму, равно n, равна 2n.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .
Полезное свойство ХИ2-распределения
Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x.
Тогда случайная величина y
равная
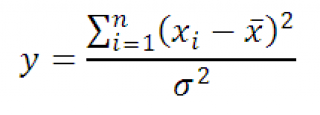
Имеет Х 2 -распределение с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом:
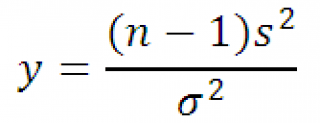
Следовательно, выборочное распределение статистики y, при выборке из нормального распределения , имеет Х 2 -распределение с n-1 степенью свободы.
Это свойство нам потребуется при . Т.к. дисперсия может быть только положительным числом, а Х 2 -распределение используется для его оценки, то y д.б. >0, как и указано в определении.
ХИ2-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Х 2 -распределения имеется специальная функция ХИ2.РАСП() , английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2 -распределение , примет значение меньше или равное х, P{X <= x}).
Примечание : Т.к. ХИ2-распределение является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.
До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП() , которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП() и ХИ2.РАСП.ПХ() перекрывают возможности этой функции. Функция ХИ2РАСП() оставлена в MS EXCEL 2010 для совместимости.
ХИ2.РАСП() является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}.
Вышеуказанные функции MS EXCEL приведены в .
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x : P{X <= x}. Это можно сделать несколькими функциями:
ХИ2.РАСП(x; n; ИСТИНА)
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
Функция ХИ2.РАСП.ПХ() возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1.
Найдем вероятность, что случайная величина Х примет значение больше заданного x : P{X > x}. Это можно сделать несколькими функциями:
1-ХИ2.РАСП(x; n; ИСТИНА)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
Обратная функция используется для вычисления альфа - , т.е. для вычисления значений x при заданной вероятности альфа , причем х должен удовлетворять выражению P{X <= x}=альфа .
Функция ХИ2.ОБР() используется для вычисления доверительных интервалов дисперсии нормального распределения .
Функция ХИ2.ОБР.ПХ() используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР() вернет такое значение случайной величины х, для которого P{X<=x}=0,05.
В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ() использовалась функция ХИ2ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат:
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Функции MS EXCEL, использующие ХИ2-распределение
Ниже приведено соответствие русских и английских названий функций:
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerse
Оценка параметров распределения
Т.к. обычно ХИ2-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
Приближение ХИ2-распределения нормальным распределением
При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).
Количественное изучение биологических явлений обязательно требует создания гипотез, с помощью которых можно объяснить эти явления. Чтобы проверить ту или иную гипотезу ставят серию специальных опытов и полученные фактические данные сопоставляют с теоретически ожидаемыми согласно данной гипотезе. Если есть совпадениеэто может быть достаточным основанием для принятия гипотезы. Если же опытные данные плохо согласуются с теоретически ожидаемыми, возникает большое сомнение в правильности предложенной гипотезы.
Степень соответствия фактических данных ожидаемым (гипотетическим) измеряется критерием соответствия хи-квадрат:
фактически наблюдаемое значение признака вi- той;теоретически ожидаемое число или признак (показатель) для данной группы,k число групп данных.
Критерий был предложен К.Пирсоном в 1900 г. и иногда его называют критерием Пирсона.
Задача. Среди 164 детей, наследовавших от одного из родителей фактор, а от другогофактор, оказалось 46 детей с фактором, 50с фактором, 68с тем и другим,. Рассчитать ожидаемые частоты при отношении 1:2:1 между группами и определить степень соответствия эмпирических данных с помощью критерия Пирсона.
Решение: Отношение наблюдаемых частот 46:68:50, теоретически ожидаемых 41:82:41.
Зададимся уровнем значимости равным 0,05. Табличное значение критерия Пирсона для этого уровня значимости при числе степеней свободы, равном оказалось равным 5,99. Следовательно гипотезу о соответствии экспериментальных данных теоретическим можно принять, так как, .
Отметим, что при вычислении критерия хи-квадрат мы уже не ставим условия о непременной нормальности распределения. Критерий хи-квадрат может использоваться для любых распределений, которые мы вольны сами выбирать в своих предположениях. В этом есть некоторая универсальность этого критерия.
Еще одно приложение критерия Пирсона это сравнение эмпирического распределения с нормальным распределением Гаусса. При этом он может быть отнесен к группе критериев проверки нормальности распределения. Единственным ограничением является тот факт, что общее число значений (вариант) при пользовании этим критерием должно быть достаточно велико (не менее 40), и число значений в отдельных классах (интервалах) должно быть не менее 5. В противном случае следует объединять соседние интервалы. Число степенй свободы при проверке нормальности распределения должно вычисляться как:.
Критерий Фишера.
Этот параметрический критерий служит для проверки нулевой гипотезы о равенстве дисперсий нормально распределенных генеральных совокупностей.
![]() Или.
Или.
При малых объемах выборок применение критерия Стьюдента может быть корректным только при условии равенства дисперсий. Поэтому прежде чем проводить проверку равенства выборочных средних значений, необходимо убедиться в правомочности использования критерия Стьюдента.
где N 1 , N 2 объемы выборок, 1 , 2 числа степеней свободы для этих выборок.
При пользовании таблицами следует обратить внимание, что число степеней свободы для выборки с большей по величине дисперсией выбирается как номер столбца таблицы, а для меньшей по величине дисперсии как номер строки таблицы.
Для уровня значимости по таблицам математической статистики находим табличное значение. Если, то гипотеза о равенстве дисперсий отклоняется для выбранного уровня значимости.
Пример. Изучали влияние кобальта на массу тела кроликов. Опыт проводился на двух группах животных: опытной и контрольной. Опытные получали добавку к рациону в виде водного раствора хлористого кобальта. За время опыта прибавки в весе составили в граммах:
|
Контроль |
|

Рассмотрим применение в MS EXCEL критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая выборка ) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной выборкой . Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием критериев согласия . Нулевой гипотезой , обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону.
Сначала рассмотрим применение критерия согласия Пирсона Х 2 (хи-квадрат) в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем - , когда задается только форма распределения, а параметры этого распределения и значение статистики Х 2 оцениваются/рассчитываются на основании одной и той же выборки .
Примечание : В англоязычной литературе процедура применения критерия согласия Пирсона Х 2 имеет название The chi-square goodness of fit test .
Напомним процедуру проверки гипотез:
- на основе выборки вычисляется значение статистики , которая соответствует типу проверяемой гипотезы. Например, для используется t -статистика (если не известно);
- при условии истинности нулевой гипотезы , распределение этой статистики известно и может быть использовано для вычисления вероятностей (например, для t -статистики это );
- вычисленное на основе выборки значение статистики сравнивается с критическим для заданного значением ();
- нулевую гипотезу отвергают, если значение статистики больше критического (или если вероятность получить это значение статистики () меньше уровня значимости , что является эквивалентным подходом).
Проведем проверку гипотез для различных распределений.
Дискретный случай
Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника.
Примечание : Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения.
Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется . Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100
В формуле предполагается, что в ячейке А7 содержится соответствующее количество выпавших шестерок в одном раунде.
Примечание : Расчеты приведены в файле примера на листе Дискретное .
Для сравнения наблюденных (Observed) и теоретических частот (Expected) удобно пользоваться .

При значительном отклонении наблюденных частот от теоретического распределения, нулевая гипотеза о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от биномиального распределения .
В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим критерий согласия Пирсона Х 2 , чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения гистограмм , использовать математически корректное утверждение.
Используем тот факт, что в силу закона больших чисел наблюденная частота (Observed) с ростом объема выборки n стремится к вероятности, соответствующей теоретическому закону (в нашем случае, биномиальному закону ). В нашем случае объем выборки n равен 100.
Введем тестовую статистику , которую обозначим Х 2:

где O l – это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E l – это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4).
Как видно из формулы, эта статистика является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим биномиальный закон ), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение статистики Х 2 (статистика Х 2 вычислена на основе случайной выборки , поэтому она является случайной величиной и, следовательно, имеет свое распределение вероятностей ).
Из многомерного аналога интегральной теоремы Муавра-Лапласа известно, что при n->∞ наша случайная величина Х 2 асимптотически с L - 1 степенями свободы.
Итак, если вычисленное значение статистики Х 2 (сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть нулевую гипотезу . Как и при проверке параметрических гипотез , предельное значение задается через уровень значимости . Если вероятность того, что статистика Х 2 примет значение меньше или равное вычисленному (p -значение ), будет меньше уровня значимости , то нулевую гипотезу можно отвергнуть.
В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х 2 примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам
=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)
Примечание : Функция ХИ2.ТЕСТ() специально создана для проверки связи между двумя категориальными переменными (см. ).
Вероятность 0,000045 существенно меньше обычного уровня значимости 0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (нулевая гипотеза о его честности отвергается).

При применении критерия Х 2 необходимо следить за тем, чтобы объем выборки n был достаточно большой, иначе будет неправомочна аппроксимация распределения статистики Х 2 . Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы Х 2 -распределения .
Для того чтобы улучшить качество применения критерия Х 2 (), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество степеней свободы ), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5).
Непрерывный случай
Критерий согласия Пирсона Х 2 можно применить так же в случае .
Рассмотрим некую выборку , состоящую из 200 значений. Нулевая гипотеза утверждает, что выборка сделана из .
Примечание : Cлучайные величины в файле примера на листе Непрерывное сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) . Поэтому, новые значения выборки генерируются при каждом пересчете листа.
Соответствует ли имеющийся набор данных можно визуально оценить .

Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в для проверки гипотезы применим Критерий согласия Пирсона Х 2 .
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5 . Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции ЧАСТОТА() , а теоретические – с помощью функции НОРМ.СТ.РАСП() .
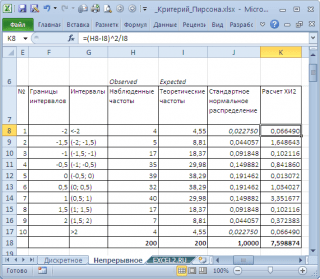
Примечание : Как и для дискретного случая , необходимо следить, чтобы выборка была достаточно большая, а в интервал попадало >5 значений.
Вычислим статистику Х 2 и сравним ее с критическим значением для заданного уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле
=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)
На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше критического значения – нулевая гипотеза не отвергается.
Ниже приведена , на которой выборка приняла маловероятное значение и на основании критерия согласия Пирсона Х 2 нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) , обеспечивающей выборку из стандартного нормального распределения ).

Нулевая гипотеза отклонена, хотя визуально данные располагаются довольно близко к прямой линии.
В качестве примера также возьмем выборку из U(-3; 3). В этом случае, даже из графика очевидно, что нулевая гипотеза должна быть отклонена.

Критерий согласия Пирсона Х 2 также подтверждает, что нулевая гипотеза должна быть отклонена.




