Коэффициент детерминации для линейной парной регрессии равен. Коэффициент вариации и коэффициент детерминации
Коэффициент множественной детерминации характеризует, на сколько процентов построенная модель регрессии объясняет вариацию значений результативной переменной относительно своего среднего уровня, т. е. показывает долю общей дисперсии результативной переменной, объяснённой вариацией факторных переменных, включённых в модель регрессии.
Коэффициент множественной детерминации также называется количественной характеристикой объяснённой построенной моделью регрессии дисперсии результативной переменной. Чем больше значение коэффициента множественной детерминации, тем лучше построенная модель регрессии характеризует взаимосвязь между переменными.
Для коэффициента множественной детерминации всегда выполняется неравенство вида:
Следовательно, включение в линейную модель регрессии дополнительной факторной переменной xn не снижает значения коэффициента множественной детерминации.
Коэффициент множественной детерминации может быть определён не только как квадрат множественного коэффициента корреляции, но и с помощью теоремы о разложении сумм квадратов по формуле:

где ESS (Error Sum Square) – сумма квадратов остатков модели множественной регрессии с n независимыми переменными:
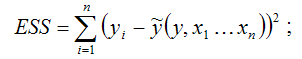
TSS (TotalSumSquare) – общая сумма квадратов модели множественной регрессии с n независимыми переменными:

Однако классический коэффициент множественной детерминации не всегда способен определить влияние на качество модели регрессии дополнительной факторной переменной. Поэтому наряду с обычным коэффициентом рассчитывают также и скорректированный (adjusted) коэффициент множественной детерминации, в котором учитывается количество факторных переменных, включённых в модель регрессии:

где n – количество наблюдений в выборочной совокупности;
h – число параметров, включённых в модель регрессии.
При большом объёме выборочной совокупности значения обычного и скорректированного коэффициентов множественной детерминации отличаться практически не будут.
24. Парный регрессионный анализ
Одним из методов изучения стохастических связей между признаками является регрессионный анализ.
Регрессионный анализ представляет собой вывод уравнения регрессии, с помощью которого находится средняя величина случайной переменной (признака-результата), если величина другой (или других) переменных (признаков-факторов) известна. Он включает следующие этапы:
выбор формы связи (вида аналитического уравнения регрессии);
оценку параметров уравнения;
оценку качества аналитического уравнения регрессии.
Наиболее часто для описания статистической связи признаков используется линейная форма. Внимание к линейной связи объясняется четкой экономической интерпретацией ее параметров, ограниченной вариацией переменных и тем, что в большинстве случаев нелинейные формы связи для выполнения расчетов преобразуют (путем логарифмирования или замены переменных) в линейную форму.
В случае линейной парной связи уравнение регрессии примет вид:
Параметры данного
уравнения а и b оцениваются по данным
статистического наблюдения x и y.
Результатом такой оценки является
уравнение:
![]() , где,- оценки параметров
a и b,
- значение
результативного признака (переменной),
полученное по уравнению регрессии
(расчетное значение).
, где,- оценки параметров
a и b,
- значение
результативного признака (переменной),
полученное по уравнению регрессии
(расчетное значение).
Наиболее часто для оценки параметров используют метод наименьших квадратов (МНК).
Метод наименьших квадратов дает наилучшие (состоятельные, эффективные и несмещенные) оценки параметров уравнения регрессии. Но только в том случае, если выполняются определенные предпосылки относительно случайного члена (u) и независимой переменной (x).
Задача оценивания параметров линейного парного уравнения методом наименьших квадратов состоит в следующем:
получить такие оценки параметров ,, при которых сумма квадратов отклонений фактических значений результативного признака - yi от расчетных значений – минимальна.
Формально критерий МНК можно записать так:
![]()
Проиллюстрируем суть данного метода графически. Для этого построим точечный график по данным наблюдений (xi ,yi, i=1;n) в прямоугольной системе координат (такой точечный график называют корреляционным полем). Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного поля. Согласно методу наименьших квадратов линия выбирается так, чтобы сумма квадратов расстояний по вертикали между точками корреляционного поля и этой линией была бы минимальной.

Математическая запись данной задачи:
![]()
Значения yi и xi i=1; n нам известны, это данные наблюдений. В функции S они представляют собой константы. Переменными в данной функции являются искомые оценки параметров - ,. Чтобы найти минимум функции 2-ух переменных необходимо вычислить частные производные данной функции по каждому из параметров и приравнять их нулю, т.е.
![]()
В результате получим систему из 2-ух нормальных линейных уравнений:

Решая данную систему, найдем искомые оценки параметров:

Правильность расчета параметров уравнения регрессии может быть проверена сравнением сумм
(возможно некоторое расхождение из-за округления расчетов).
Знак коэффициента регрессии b указывает направление связи (если b>0, связь прямая, если b <0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Формально значение параметра а – среднее значение y при х равном нулю. Если признак-фактор не имеет и не может иметь нулевого значения, то вышеуказанная трактовка параметра а не имеет смысла.
Оценка тесноты связи между признаками осуществляется с помощью коэффициента линейной парной корреляции - rx,y. Он может быть рассчитан по формуле:

Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
Область допустимых значений линейного коэффициента парной корреляции от –1 до +1. Знак коэффициента корреляции указывает направление связи. Если rx, y>0, то связь прямая; если rx, y<0, то связь обратная.
Если данный коэффициент по модулю близок к единице, то связь между признаками может быть интерпретирована как довольно тесная линейная. Если его модуль равен единице ê rx , y ê =1, то связь между признаками функциональная линейная. Если признаки х и y линейно независимы, то rx,y близок к 0.
Для оценки качества полученного уравнения регрессии рассчитывают теоретический коэффициент детерминации – R2yx:

где d 2 – объясненная уравнением регрессии дисперсия y;
e 2- остаточная (необъясненная уравнением регрессии) дисперсия y;
s 2 y - общая (полная) дисперсия y .
Коэффициент детерминации характеризует долю вариации (дисперсии) результативного признака y, объясняемую регрессией (а, следовательно, и фактором х), в общей вариации (дисперсии) y. Коэффициент детерминации R2yx принимает значения от 0 до 1. Соответственно величина 1-R2yx характеризует долю дисперсии y, вызванную влиянием прочих неучтенных в модели факторов и ошибками спецификации.
При парной линейной регрессии R 2yx=r2 yx.
Отклонений зависимой переменной от её среднего значения. Зависимая переменная объясняется (прогнозируется) с помощью функции от объясняющих переменных, в частном случае является квадратом коэффициента корреляции между зависимой переменной и её прогнозными значениями с помощью объясняющих переменных. Тогда можно сказать, что R 2 показывает, какая доля дисперсии результативного признака объясняется влиянием объясняющих переменных.
Формула для вычисления коэффициента детерминации:
где yi - наблюдаемое значение зависимой переменной, а fi - значение зависимой переменной предсказанное по уравнению регрессии -среднее арифметическое зависимой переменной.
[править]Проблемы и общие свойства R 2
[править]Интерпретация
Иногда показателям тесноты связи можно дать качественную оценку (шкала Чеддока):
Количественная мера тесноты связи | Качественная характеристика силы связи |
Умеренная |
|
Заметная |
|
Весьма высокая |
Функциональная связь возникает при значении равном 1, а отсутствие связи - 0. При значениях показателей тесноты связи меньше 0,7 величина коэффициента детерминации всегда будет ниже 50 %. Это означает, что на долю вариации факторных признаков приходится меньшая часть по сравнению с остальными неучтенными в модели факторами, влияющими на изменение результативного показателя. Построенные при таких условиях регрессионные модели имеют низкое практическое значение.
[править]Общие свойства для МНК регрессии
Линейная множественная регрессия методом наименьших квадратов (МНК) - наиболее распространённый случай использования коэффициента детерминации R 2.
Линейная множественная МНК регрессия имеет следующие общие свойства :
1. Чем ближе значение к 1 тем ближе модель к эмпирическим наблюдениям.
2. С увеличением количества объясняющих переменных увеличивается R 2.
[править]Общие свойства для МНК регрессии со свободным членом (единичным фактором)
Для случая наличия в такой регрессии свободного члена коэффициент детерминации обладает следующими свойствами:
1. принимает значения из интервала (отрезка) .
2. в случае парной линейной регрессионной МНК модели коэффициент детерминации равен квадрату коэффициента корреляции, то есть R 2 = r 2. А в случае множественной МНК регрессии R 2 = r (y ;f )2. Также это квадрат корреляции Пирсона между двумя переменными. Он выражает количество дисперсии, общей между двумя переменными.
3. R
2 можно разложить по вкладу каждого фактора в значение R
2, причём вклад каждого такого фактора будет положительным. Используется разложение:  , где r
0j
- выборочный коэффициент корреляции зависимой и соответствующей второму индексу объясняющей переменной.
, где r
0j
- выборочный коэффициент корреляции зависимой и соответствующей второму индексу объясняющей переменной.
4. R
2 связан с проверкой гипотезы о том, что истинные значения коэффициентов при объясняющих переменных равны нулю, в сравнении с альтернативной гипотезой, что не все истинные значения коэффициентов равны нулю. Тогда случайная величина ![]() имеет F-распределение с (k-1) и (n-k) степенями свободы.
имеет F-распределение с (k-1) и (n-k) степенями свободы.
[править]Мнимая регрессия
Значения R 2, , Быль" href="/text/category/bilmz/" rel="bookmark">быль проверено или сопоставлено с использованием R 2 и его модификаций.
[править]Решение проблем или модификации R 2
[править]R 2-скорректированный (adjusted)
Для того, чтобы исследователи не увеличивали R
2 с помощью добавления посторонних факторов, R
2 заменяется на скорректированный https://pandia.ru/text/79/148/images/image006_10.gif" alt="R_{extended}^2" width="72" height="23 src=">, который будет совпадать с исходным для случая МНК регрессии со свободным членом, и для которого будут продолжать выполняться четыре свойства перечисленые выше. Суть этого метода заключается рассмотрении проекции единичного вектора на плоскость объясняющих переменных .
Для случая регрессии без свободного члена:
,
где X - матрица nxk значений факторов, P
(X
) = X
* (X
" * X
) − 1 * X
" - проектор на плоскость X, https://pandia.ru/text/79/148/images/image006_10.gif" alt="R_{extended}^2" width="72" height="23">с условием небольшой модификации
, также подходит для сравнения между собой регрессий построенных с помощью: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК).
[править]R 2-истинный (несмещённый)
<---Будет добавлен---!>
[править]Прочие используемые критерии
AIC - информационный критерий Акаике - применяется исключительно для сравнения между моделями. Чем меньше значение тем лучше. Часто используется в виде сравнения моделей временных рядов с разным количеством лагов.![]() . Даёт меньший штраф за включение лишних лагов в модель, чем BIC.
. Даёт меньший штраф за включение лишних лагов в модель, чем BIC.
BIC - информационный критерий Шварца - используется и интерпретируется аналогично AIC.
. Даёт больший штраф за включение лишних лагов в модель, чем BIC (см. формулу).
[править]См. также
§ Коэффициент корреляции
§ Корреляция
§ Мультиколлинеарность
§ Дисперсия случайной величины
§ Метод группового учета аргументов
§ Регрессионный анализ
[править]Примечания
1. 1 2 , Эконометрика. Начальный курс.. - 6,7,8-е изд., доп. и перераб.. - Москва: Дело, 2004. - Т. "". - 576 с. - ISBN -X
2. 1 2 Распространение коэффициента детерминации на общий случай линейной регрессии, оцениваемой с помощью различных версий метода наименьших квадратов (рус., англ.) //ЦЕМИ РАН Экономика и математические методы . - Москва: ЦЕМИ РАН, 2002. - В. 3. - Т. 38. - С. 107-120.
3. , Прикладная статистика. Основы эконометрики (в 2-х т.). - ??. - Москва: Юнити-Дана (проект TASIS), 2001. - Т. "1,2". - 1088 с. - ISBN -8
4. Выбор регрессии максимизирующий несмещённую оценку коэффициента детерминации (рус., англ.) // Прикладная эконометрика. - Москва: Маркет ДС, 2008. - В. 4. - Т. 12. - С. 71-83.
[править]Ссылки
§ Глоссарий статистических терминов
§ Прикладная эконометрика (журнал)
Коэффициент детерминации ( - R-квадрат ) - это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью. Более точно - это единица минус доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной по признакам дисперсии зависимой переменной) в дисперсии зависимой переменной. В случае линейной зависимости является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели линейной регрессии с одним признаком коэффициент детерминации равен квадрату обычного коэффициента корреляции между и .
Определение и формула
Истинный коэффициент детерминации модели зависимости случайной величины от признаков определяется следующим образом:
где - условная (по признакам ) дисперсия зависимой переменной (дисперсия случайной ошибки модели).
В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации):
- сумма квадратов регрессионных остатков, - общая дисперсия, - соответственно, фактические и расчетные значения объясняемой переменной, - выборочное вреднее.В случае линейной регрессии с константой , где - объяснённая сумма квадратов, поэтому получаем более простое определение в этом случае. Коэффициент детерминации - это доля объяснённой дисперсии в общей :
.Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу.
Интерпретация
Недостатки и альтернативные показатели
Основная проблема применения (выборочного) заключается в том, что его значение увеличивается (не уменьшается) от добавления в модель новых переменных, даже если эти переменные никакого отношения к объясняемой переменной не имеют. Поэтому сравнение моделей с разным количеством признаков с помощью коэффициента детерминации, вообще говоря, некорректно. Для этих целей можно использовать альтернативные показатели.
Скорректированный (adjusted)
Для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику обычно используется скорректированный коэффициент детерминации , в котором используются несмещённые оценки дисперсий:
который даёт штраф за дополнительно включённые признаки, где - количество наблюдений, а - количество параметров.
Данный показатель всегда меньше единицы, но теоретически может быть и меньше нуля (только при очень маленьком значении обычного коэффициента детерминации и большом количестве признаков), поэтому интерпретировать его как долю объясняемой дисперсии уже нельзя. Тем не менее, применение показателя в сравнении вполне обоснованно.
Для моделей с одинаковой зависимой переменной и одинаковым объемом выборки сравнение моделей с помощью скорректированного коэффициента детерминации эквивалентно их сравнению с помощью остаточной дисперсии или стандартной ошибки модели .
Обобщённый (extended)
В случае отсутствия в линейной множественной МНК регрессии константы свойства коэффициента детерминации могут нарушаться для конкретной реализации . Поэтому модели регрессии со свободным членом и без него нельзя сравнивать по критерию . Эта проблема решается с помощью построения обобщённого коэффициента детерминации , который совпадает с исходным для случая МНК регрессии со свободным членом. Суть этого метода заключается рассмотрении проекции единичного вектора на плоскость объясняющих переменных.
Коэффициент детерминации
Коэффициент детерминации ( - R-квадрат ) - это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью зависимости, то есть объясняющими переменными. Более точно - это единица минус доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной по факторам дисперсии зависимой переменной) в дисперсии зависимой переменной. Его рассматривают как универсальную меру связи одной случайной величины от множества других. В частном случае линейной зависимости является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели парной линейной регрессии коэффициент детерминации равен квадрату обычного коэффициента корреляции между y и x .
Определение и формула
Истинный коэффициент детерминации модели зависимости случайной величины y от факторов x определяется следующим образом:
где - условная (по факторам x) дисперсия зависимой переменной (дисперсия случайной ошибки модели).
В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации):
где -сумма квадратов остатков регрессии, - фактические и расчетные значения объясняемой переменной.
Общая сумма квадратов.
В случае линейной регрессии с константой , где - объяснённая сумма квадратов, поэтому получаем более простое определение в этом случае - коэффициент детерминации - это доля объяснённой суммы квадратов в общей :
Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу.
Интерпретация
1. Коэффициент детерминации для модели с константой принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50% (в этом случае коэффициент множественной корреляции превышает по модулю 70%). Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими (коэффициент корреляции превышает 90%). Значение коэффициента детерминации 1 означает функциональную зависимость между переменными.
2. При отсутствии статистической связи между объясняемой переменной и факторами, статистика для линейной регрессии имеет асимптотическое распределение , где - количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределёнными случайными ошибками статистика имеет точное (для выборок любого объёма) распределение Фишера (см. F-тест). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
Недостаток и альтернативные показатели
Основная проблема применения (выборочного) заключается в том, что его значение увеличивается (не уменьшается) от добавления в модель новых переменных, даже если эти переменные никакого отношения к объясняемой переменной не имеют! Поэтому сравнение моделей с разным количеством факторов с помощью коэффициента детерминации, вообще говоря, некорректно. Для этих целей можно использовать альтернативные показатели.
Скорректированный (adjusted)
Для того, чтобы была возможность сравнивать модели с разным числом факторов так, чтобы число регрессоров (факторов) не влияло на статистику обычно используется скорректированный коэффициент детерминации , в котором используются несмещённые оценки дисперсий:
который даёт штраф за дополнительно включённые факторы, где n - количество наблюдений, а k - количество параметров.
Данный показатель всегда меньше единицы, но теоретически может быть и меньше нуля (только при очень маленьком значении обычного коэффициента детерминации и большом количестве факторов). Поэтому теряется интерпретация показателя как "доли". Тем не менее, применение показателя в сравнении вполне обоснованно.
Для моделей с одинаковой зависимой переменной и одинаковым объемом выборки сравнение моделей с помощью скорректированного коэффициента детерминации эквивалентно их сравнению с помощью остаточной дисперсии или стандартной ошибки модели . Разница только в том, что последние критерии чем меньше, тем лучше.
Информационные критерии
AIC
- информационный критерий Акаике - применяется исключительно для сравнения моделей. Чем меньше значение тем лучше. Часто используется для сравнения моделей временных рядов с разным количеством лагов.
, где k
- количество параметров модели.
BIC
или SC
- байесовский информационный критерий Шварца - используется и интерпретируется аналогично AIC.
. Даёт больший штраф за включение лишних лагов в модель, чем AIC.
-обобщённый (extended)
В случае отсутствия в линейной множественной МНК регрессии константы свойства коэффициента детерминации могут нарушаться для конкретной реализации . Поэтому модели регрессии со свободным членом и без него нельзя сравнивать по критерию . Эта проблема решается с помощью построения обобщённого коэффициента детерминации , который совпадает с исходным для случая МНК регрессии со свободным членом, и для которого выполняются четыре свойства перечисленные выше. Суть этого метода заключается рассмотрении проекции единичного вектора на плоскость объясняющих переменных.
Для случая регрессии без свободного члена:
,
где X - матрица nxk значений факторов, - проектор на плоскость X, , где - единичный вектор nx1.
с условием небольшой модификации , также подходит для сравнения между собой регрессий построенных с помощью: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК).
Замечание
Высокие значения коэффициента детерминации, вообще говоря, не свидетельствуют о наличии причинно-следственной зависимости между переменными (также как и в случае обычного коэффициента корреляции). Например, если объясняемая переменная и факторы, на самом деле не связанные с объясняемой переменой, имеют возрастающую динамику, то коэффициент детерминации будет достаточно высок. Поэтому логическая и смысловая адекватность модели имеют первостепенную важность. Кроме того, необходимо использовать критерии для всестороннего анализа качества модели.
См. также
Примечания
Ссылки
- Прикладная эконометрика (журнал)
Wikimedia Foundation . 2010 .
- Коэффициент де Ритиса
- Коэффициент естественной освещённости
Смотреть что такое "Коэффициент детерминации" в других словарях:
КОЭФФИЦИЕНТ ДЕТЕРМИНАЦИИ - оценка качества (объясняющей способности) уравнения регрессии, доля дисперсии объясненной зависимой переменной у: R2= 1 Sum(yi yzi)2 / Sum(yi y)2 , где yi наблюдаемое значение зависимой переменной y, yzi значение зависимой переменной,… … Социология: Энциклопедия
Коэффициент детерминации - квадрат коэффициента линейной корреляции Пирсона, интерпретируется как доля дисперсии зависимой переменной, объясненной посредством независимой переменной … Социологический словарь Socium
Коэффициент детерминации - Мера того, насколько хорошо соотносятся зависимые и независимые переменные в регрессивном анализе. Например, процент от изменения доходности актива, объясняемый доходностью рыночного портфеля … Инвестиционный словарь
Коэффициент детерминации - (COEFFICIENT OF DETERMINATION) определяется при построении линейной регрессионной зависимости. Равен доле дисперсии зависимой переменной, связанной с вариаций независимой переменной … Финансовый глоссарий
Коэффициент корреляции - (Correlation coefficient) Коэффициент корреляции это статистический показатель зависимости двух случайных величин Определение коэффициента корреляции, виды коэффициентов корреляции, свойства коэффициента корреляции, вычисление и применение… … Энциклопедия инвестора
При выполнении процедуры проверки значимости коэффициента детерминации выдвигается нулевая гипотеза Нo против альтернативной H1 которые заключаются в следующем:
Нo: существенного различия между выборочным коэффициентом детерминации и коэффициентом детерминации генеральной совокупности B(r) = 0 нет.
Эта гипотеза равносильна гипотезе Нo: β1 = β2 = … = βm = 0, т. е. ни одна из объясняющих переменных, включенных в регрессию, не оказывает существенного влияния на зависимую переменную.
Н1: выборочный коэффициент детерминации существенно больше коэффициента детерминации генеральной совокупности В(г) = 0.
Из постановки задачи ясно, что следует использовать одностороннюю критическую область. Принятие гипотезы Н1 означает, что по крайней мере одна из m объясняющих переменных, включенных в регрессию, оказывает существенное влияние на переменную у.
Для оценки значимости парного коэффициента детерминации используется статистика
Имеющая F-распределение Фишера с f1 = m = 1 и f2 = n – 2 степенями свободы. Значение статистики, вычисленное вышеприведенной формуле, сравнивается с критическим значением этой статистики при заданном уровне значимости £ и соответствующем числе степеней свободы. Если F > Ff1; f2;£, то вычисленный коэффициент детерминации значимо отличается от нуля. Этот вывод обеспечивается с вероятностью 1 - £.
28 Проверка значимости коэффициентов регрессии
Проверка статистической значимости параметров регрессионного уравнения (коэффициентов регрессии) выполняется по t -критерию Стьюдента, который рассчитывается по формуле:
где P
- значение параметра;
S p
- стандартное отклонение параметра.
Рассчитанное значение критерия Стьюдента сравнивают с его табличным значением при выбранной доверительной вероятности (как правило, 0.95) и числе степеней свободы N -k -1, где N -число точек, k -число переменных в регрессионном уравнении (например, для линейной моделиY=A*X+B подставляем k =1).
Если вычисленное значение t p выше, чем табличное, то коэффициент регрессии является значимым с данной доверительной вероятностью. В противном случае есть основания для исключения соответствующей переменной из регрессионной модели.
Величины параметров и их стандартные отклонения обычно рассчитываются в алгоритмах, реализующих метод наименьших квадратов.
29 Проверка общего качества уравнения регрессии. Коэффициент детерминации. Проверка значимости коэффициента детерминации
После проверки значимости каждого коэффициента регрессии обычно проверяется общее качество уравнения регрессии. Для этой цели, как и в случае парной регрессии, используется коэффициент детерминации R 2 , который рассчитывается по формуле:

В общем случае 0 < R 2 < 1. Чем ближе этот коэффициент к единице, тем больше уравнение регрессии объясняет поведение Y. Поэтому естественно желание построить регрессию с наибольшим R 2 .
Для множественной регрессии коэффициент детерминации является неубывающей функцией числа объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R . Действительно, каждая следующая объясняющая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведение зависимой переменной. Это уменьшает (в худшем случае не увеличивает) область неопределенности в поведении Y.
Коэффициент детерминации ()- это квадрат множественного коэффициента корреляции. Он показывает, какая доля дисперсии результативного признака объясняется влиянием независимых переменных.
Формула для вычисления коэффициента детерминации:
![]()
где - выборочные данные, а - соответствующие им значения модели.
Также это квадрат корреляции Пирсона между двумя переменными. Он выражает количество дисперсии, общей между двумя переменными.
Коэффициент принимает значения из интервала . Чем ближе значение к 1 тем ближе модель к эмпирическим наблюдениям.
В случае парной линейной регрессионной модели коэффициент детерминации равен квадрату коэффициента корреляции, то есть .
После оценки индивидуальной статистической значимости каждого из коэффициентов регрессии обычно анализируется совокупная значимость коэффициентов. Такой анализ осуществляется на основе проверки гипотезы об общей значимости - гипотезы об одновременном равенстве нулю всех коэффициентов регрессии при объясняющих переменных:
0: β 0 = β 1 = β 2 = ... = β m =0
Если данная гипотеза не отклоняется, то делается вывод о том, что совокупное влияние всех m объясняющих переменных X 1 , Х 2 , ..., Х m модели на зависимую переменную Y можно считать статистически несущественным, а общее качество уравнения регрессии невысоким.
Проверка данной гипотезы осуществляется на основе дисперсионного анализа сравнения объясненной и остаточной дисперсий.
H 0: (объясненная дисперсия) = (остаточная дисперсия),
H 1: (объясненная дисперсия) > (остаточная дисперсия).
Строится F-статистика:

где - объясненная дисперсия; ![]() - остаточная дисперсия. При выполнении предпосылок МНК построенная F-статистика имеет распределение Фишера с числами степеней свободы ν 1 =m, ν 2 = n-m-1. Поэтому, если при требуемом уровне значимости α F набл > F α,m,n-m-1 = F кр (критическая точка распределения Фишера), то H 0 отклоняется в пользу H 1 . Это означает, что объясненная дисперсия существенно больше остаточной дисперсии, а следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной Y.
- остаточная дисперсия. При выполнении предпосылок МНК построенная F-статистика имеет распределение Фишера с числами степеней свободы ν 1 =m, ν 2 = n-m-1. Поэтому, если при требуемом уровне значимости α F набл > F α,m,n-m-1 = F кр (критическая точка распределения Фишера), то H 0 отклоняется в пользу H 1 . Это означает, что объясненная дисперсия существенно больше остаточной дисперсии, а следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной Y.
Однако на практике чаще вместо указанной гипотезы проверяют тесно связанную с ней гипотезу о статистической значимости коэффициента детерминации R 2:
Для проверки данной гипотезы используется следующая F-статистика:
![]()
Величина F при выполнении предпосылок МНК и при справедливости. Но имеет распределение Фишера, аналогичное распределению F-статистики.
Анализ статистики F позволяет сделать вывод о том, что для принятия гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии коэффициент детерминации R 2 не должен существенно отличаться от нуля. Его критическое значение уменьшается при росте числа наблюдений и может стать сколь угодно малым.
30. Путь, полный путь, критический путь, определение критического пути четырехсекторным методом.
Путь – любая последовательность работ, в которой конечное событие каждой работы совпадает с начальным событием следующий за ней работы.
Полный путь L – любой путь, начало которого совпадает с исходным событием сети, а конец – с завершающим.
Критич. путь - полный путь, имеющий наибольшую длину (продолжительность) из всех полных путей. Eгo длина опред. срок выполнения работ по сетевому графику. В rрафике может быть несколько критич. путей. Работы, лежащие на критич. пути, наз. критическими. Увеличение продолжительности критич. работ соответств. увеличивает общую продолжительность работ по СГ.
При четырехсекторном способе определения критического пути кружок сетевого графика, обозначающий событие, делится на четыре сектора (рис.а). В верхнем ставится номер события i, в левом – наиболее раннее из возможных время свершения события tp(i), в правом – наиболее позднее из допустимых время свершения события tп(i), в нижнем – резерв времени данного события R(i).

Рисунок: а) обозначения в вершине графика; б) сетевой график.
Раннее время свершения события tp(i) определяется продолжительностью максимального пути max(t) до (i), предшествующего событию i: tp(i)=max(t) до (i).
Послойно, переходя от исходного события до конечного, определим tp(i). Всегда для начального события tp(1)=0.
Для события 3 (рис., б) – tp(3)=max{1+3,0+5}=5; для события 4 – tp(4)=max{1+2,5+6}=11.
Длина критического пути Lкр=11. Послойно, переходя от конечного события до начального, определим tп(i). Всегда для конечного события tп(4)=t(Lкр)=11. Позднее время свершения события tп(i) определяется временем достаточным для выполнения работ, следующих за этим событием, т.е. зная продолжительность максимального из последующих за событием i путей max(t) после (i) и продолжительность критического пути t(Lкр), можно найти tп(i)= t(Lкр)-max(t) после (i).
Для события 2 – tп(3)=11-max{3+6,2}=2.
Для критического пути время раннего свершения события tp(i) равно времени позднего свершения этого события tп(i), т.е. tp(i)= tп(i). Зная ранние и поздние сроки свершения событий сетевого графика, легко выявить резерв времени каждого из них R(i)= tп(i)- tp(i).
Резерв времени события показывает максимально допустимое время, на которое можно отодвинуть момент его свершения, не вызывая увеличения критического пути. События критического пути резерва времени не имеют.
Связь параметров сетевого графика для событий и работ показана в таблице.
Таблица - Расчет параметров работ
Резерв времени для работы R(ij) определяется по формуле: R(ij)= tп(j)- tр(i)-tij.
31. Расчет временных параметров событий в задачах сетевого планирования.
При анализе сетевого графика прежде всего вычисляют его временные параметры. К основным временным параметрам относятся:
Продолжительность критического пути (критический срок);
Сроки свершения и резервы сетей;
Сроки выполнения отдельных работ и их резервы времени.
Основные временные параметры
Ранний срок свершения событий – самый ранний момент, в котором завершаются все работы предшествующие этому событию. Рассчитывается по формуле:
Где - ранний срок свершения события i.
Продолжительность работы i, j.
Подмножество, включающее все работы входящие в событие j.
Поздний срок свершения события – такой предельный момент, после которого остаётся столько времени, сколько необходимо для выполнения всех работ следующих за этим событием.
Рассчитывается по формуле: .
Резерв времени события показывает, на какой предельно допустимый срок может задержаться свершение событий i без нарушения сроков наступления завершающего события.
R(i)= ![]()
Резервы времени критических событий=0
Ранний срок начала работы совпадает с ранним сроком свершения событий i.
Ранний срок окончания работы определяется по формуле:
Поздний срок окончания работы совпадает с поздним сроком свершения события j.
Поздний срок начала работы определяется по формуле:
Полный резерв времени работы - это максимальный запас времени, на которое можно задержать начало работы или увеличить её продолжительность при условии, что весь комплекс работ будет завершён в критический срок.
Свободный резерв времени работы - это максимальный запас времени, на который можно отсрочить или увеличить её продолжительность при условии, что не нарушаться ранние сроки начала всех последующих работ.
Критические работы, как и критические события резервов не имеют.
Расчёт временных параметров сетевой модели проводят в 4 этапа:
1) прямой – вычисления начинаются с исходного события и продолжаются пока не будет достигнуто завершающее событие. Для каждого события вычисляется ранний срок его свершения.
2) обратный – вычисление начинается с обратного события и продолжается пока не будет достигнуто исходное событие. Для каждого события рассчитывается поздний срок его свершения.
3) вычисляются резервы времени событий и выделяется критический путь. Критический путь – это самый продолжительный путь, который проходит через события, резерв времени которых равен нулю.
4) строится сводная таблица временных параметров события.
32. Регрессии. Нелинейные по переменным и их построение.
Чтобы написать ту или иную зависимость прим. ур-ие регрессии – ур-ие, связыв. между собой фактор признаки и результативные признаки. Ур-ие регрессии бывают линейные и нелинейные. Сама регрессия
бывает парная
(зав-сть между 1-им фактор признаком и результатом) y = y(x) ; и множественная
y = a + bx (парная линейная регрессия, т.к. х и у участвуют в 1-ой степени, а и b – параметры рег. имеющие эк. смысл).При иссл. соц.-экон. явл. и процессов далеко не все зависимости можно описать с помощью лин. связи. Т.О. в ЭММ широко использ. класс нелин. моделей регрессии, кот. делятся на 2 класса:1) модели регрессии, нелин. относительно включенных в анализ независ. переменных, но линейные по оцениваемым параметрам;2) модели регрессии, нелинейные по оцениваемым параметрам.Для оценки параметров нелинейных моделей используют два подхода. 1.основан на линеаризации модели (с помощью подходящих преобразований исходных переменных исследуемую зависимость представляют в виде линей. соотношения между преобразованными переменными). 2.применяют в случаях, когда подобрать соответствующее линеаризующее преобразование не удается. Тогда исп. методы нелин. оптимизации на основе исходных переменных. Оценка параметров регрессии, нелинейной по переменным, включенным в анализ, но линейной по оцениваемым параметрам, проводится с помощью МНК путем решения системы линейных алгебр.уравнений. К моделям регрессии, нелинейным относительно включённых в анализ независимых переменных (но линейных по оцениваемым параметрам), относятся полиномы выше второго порядка и гиперболическая функция. Эти модели представляют собой что зависимая переменная yi линейно связана с параметрами модели.Полиномы или полин. функции примен. при анализе процессов с монотонным развитием и отсутствием пределов роста. (нап.натур.показатели пром. про-ва). Полин. функции характер. отсутствием явной зависимости приростов факторных переменных от значений результативной переменной yi.Общий вид полинома n-го порядка (n-ой степени): Чаще всего в ЭММ примен. полином второго порядка (параболическая функция), характ. равноускоренное развитие процесса (равноускоренный рост или снижение уровней).: Гиперболическая функция характеризует нелин. зависимость между результативной переменной yi и факторной переменной xi, однако, эта функция является лин.по оцениваемым параметрам.(модель зависимости затрат на единицу продукции от объёма производства)Гиперболоид или гиперболическая функция имеет вид:  Данная гиперб. функция является равносторонней.Неизвестные параметры модели регрессии, нелинейной по факторным переменным, можно найти только после того, как модели будет приведена к линейному виду.Для того чтобы оценить неизвестные параметры нелин. регрессионной модели необходимо привести её к линейному виду. Суть процесс линеаризации нелин. по факторным переменным моделей регрессии заключается в замене нелин. факторных переменных на лин. переменные.Рассмотрим процесс линеаризации полиномиальной функции порядка n: Заменим все факторные переменные на линейные следующим образом:x=c1; x2=c2; x3=c3; … xn=cn.Тогда модель множественной регрессии можно записать в виде:yi= Рассмотрим процесс линеаризации гиперболической функции:
Данная гиперб. функция является равносторонней.Неизвестные параметры модели регрессии, нелинейной по факторным переменным, можно найти только после того, как модели будет приведена к линейному виду.Для того чтобы оценить неизвестные параметры нелин. регрессионной модели необходимо привести её к линейному виду. Суть процесс линеаризации нелин. по факторным переменным моделей регрессии заключается в замене нелин. факторных переменных на лин. переменные.Рассмотрим процесс линеаризации полиномиальной функции порядка n: Заменим все факторные переменные на линейные следующим образом:x=c1; x2=c2; x3=c3; … xn=cn.Тогда модель множественной регрессии можно записать в виде:yi= Рассмотрим процесс линеаризации гиперболической функции:  Данная функция может быть приведена к линейному виду путём замены нелин.факторной переменной 1/x на лин.переменную с. Тогда модель регрессии можно записать в виде:yi=Следовательно, модели регрессии, нелин. относительно включенных в анализ независимых переменных, но лин. по оцениваемым параметрам, могут быть преобразованы к лин. виду. Это позволяет применять к линеаризованным моделям регрессии классические методы определения неизвестных параметров модели (метод наименьших квадратов), а также методы проверки различных гипотез.33. Резервы времени работ в задачах сетевого планирования
Путь характеризуется двумя показателями - продолжительностью и резервом. Для событий рассчитывают три характеристики: ранний и поздний срок совершения события, а также его резерв.
Данная функция может быть приведена к линейному виду путём замены нелин.факторной переменной 1/x на лин.переменную с. Тогда модель регрессии можно записать в виде:yi=Следовательно, модели регрессии, нелин. относительно включенных в анализ независимых переменных, но лин. по оцениваемым параметрам, могут быть преобразованы к лин. виду. Это позволяет применять к линеаризованным моделям регрессии классические методы определения неизвестных параметров модели (метод наименьших квадратов), а также методы проверки различных гипотез.33. Резервы времени работ в задачах сетевого планирования
Путь характеризуется двумя показателями - продолжительностью и резервом. Для событий рассчитывают три характеристики: ранний и поздний срок совершения события, а также его резерв.
Ранний срок свершения события определяется величиной наиболее длительного отрезка пути от исходного до рассматриваемого события, причем tр(1)=0, a tр(N)=tKp(L):
tр(j)=max{tр(j)+(i,j)}; j=2,…,N
Поздний срок свершения события характеризует самый поздний допустимый срок, к которому должно совершиться событие, не вызывая при этом срыва срока свершения конечного события:
tn(i)=min{tn(i)-t(i,j)}; j=2,…,N-1
Этот показатель определяется «обратным ходом», начиная с завершающего события, с учетом соотношения tn(N)=tp(N).
Все события, за исключением событий, принадлежащих критическому пути, имеют резерв R(i):
R(i)=tn(i)-tp(i)
Резерв определяется как разность между длинами критического и рассматриваемого путей. Из этого определения следует, что работы, лежащие на критическом пути, и сам критический путь имеют нулевой резерв времени. Резерв времени пути показывает, на сколько может увеличиться продолжительность работ, составляющих данный путь, без изменения продолжительности общего срока выполнения всех работ.Резерв показывает, на какой предельно допустимый срок можно задержать наступление этого события, не вызывая при этом увеличения срока выполнения всего комплекса работ. Для всех работ (i,j) на основе ранних и поздних сроков свершения всех событий можно определить показатели:
Ранний срок начала- tpn(i,j)=p(i) ;
Ранний срок окончания - tpo(i,j)=tp(i)+t(i,j);
Поздний срок окончания - tno(U)=tn(j);
Поздний срок начала -tпн(i,j)=tn(j)-t(i,j);
Полный резерв времени -Rn(i,j)=tn(j)-tp(i)-t(i,j);
Независимый резерв -
Rн(i,j)=max{0; tp(j)–tn(i)-t(i,j)}=max{0;Rn(i,j)-R(i)-R(j)}.
Полный резерв времени показывает, на сколько можно увеличить время выполнения конкретной работы при условии, что срок выполнения всего комплекса работ не изменится.
Независимый резерв времени соответствует случаю, когда все предшествующие работы заканчиваются в поздние сроки, а все последующие - начинаются в ранние сроки. Использование этого резерва не влияет на величину резервов времени других работ.
34. Сроки раннего и позднего начала и окончания работ в задачах сетевого планирования
Работа – это некоторый процесс, приводящий к достижению определенного результата и требующий затрат каких-либо ресурсов, имеет протяженность во времени.
Начало и окончание любой работы описываются парой событий, которые называются начальным и конечным событиями
![]()
Временные параметры работ определяются на основе ранних и поздних сроков событий:
· ![]() – ранний срок начала работы;
– ранний срок начала работы;
· ![]() – ранний срок окончания работы;
– ранний срок окончания работы;
· ![]() – поздний срок окончания работы;
– поздний срок окончания работы;
· – поздний срок начала работы;
35. Сроки совершения событий в задачах сетевого планирования
Событие – момент времени, когда завершаются одни работы и начинаются другие. Событие представляет собой результат проведенных работ и, в отличие от работ, не имеет протяженности во времени. Например, фундамент залит бетоном, комплектующие поставлены, отчеты сданы...
В сетевой модели имеется начальное событие (с номером 1), из которого работы только выходят, и конечное событие (с номером N), в которое работы только входят.
Путь – это последовательность работ в сетевом графике, в которой конечное событие одной работы совпадает с начальным событием следующей за ней работы. Полный путь – это путь от исходного до завершающего события. Критический путь –максимальный по продолжительности полный путь. Работы, лежащие на критическом пути, называют критическими. Критические работы имеют нулевые свободные и полные резервы. Подкритический путь – полный путь, ближайший по длительности к критическому пути. Сетевой график может содержать не один, а несколько критических путей. Критическими называются также работы и события, расположенные на этом пути. Резервный интервал от t до t* для событий, лежащих на критическом пути, равен 0. Для завершающего события сетевого графика поздний срок свершения события должен равняться его раннему сроку, т. е. tп = t*п.
– ранний срок наступления события i, минимально необходимый для выполнения всех работ, которые предшествуют событию i
– поздний срок наступления события i, превышение которого вызовет аналогичную задержку наступления завершающего события сети;
![]() – резерв события i, т.е. время, на которое может быть отсрочено наступление события i без нарушения сроков завершения проекта в целом.
– резерв события i, т.е. время, на которое может быть отсрочено наступление события i без нарушения сроков завершения проекта в целом.
Ранние сроки свершения событий рассчитываются от исходного (И) к завершающему (З) событию следующим образом:

 1) для исходного события И ;
1) для исходного события И ;
2) для всех остальных событий I
Межотраслевые балансы могут разрабатываться на плановый и отчетный период в натуральном, натурально-стоимостном и стоимостном выражении.
МОБ в натуральном выражении (в физических измерителях) охватывают только важнейшие виды продукции. Натурально-стоимостной (баланс смешанного типа) охватывает весь общественный продукт. Стоимостной баланс характеризует процесс воспроизводства в денежном выражении.
МОБ представлен в виде системы линейных уравнений. МОБ представляет собой таблицу, в которой отражен процесс формирования и использования совокупного общественного продукта в отраслевом разрезе. Таблица показывает структуру затрат на производство каждого продукта и структуру его распределения в экономике. По столбцам отражается стоимостной состав валового выпуска отраслей экономики по элементам промежуточного потребления и добавленной стоимости. По строкам отражаются направления использования ресурсов каждой отрасли.
В. Леонтьев создал научно обоснованный метод "затраты-выпуск", который позволяет анализировать межотраслевые связи в национальном хозяйстве и определять возможные направления оптимизации отраслевой структуры.
В общем виде модель МОБ Леонтьева имеет следующий вид:
где X- объем производства какой-либо отрасли;Y - конечный продукт этой отрасли;А - матрица технологических коэффициентов прямых затрат, aij, которые показывают, сколько продукции отрасли необходимо затратить для производства единицы продукции отрасли.
37. Типы данных и виды переменных в эконометрических задачах
При эконометрическом моделировании экономических процессов используют следующие типы эмпирических (статистических) данных:
а) пространственные;
б) временные.
Пространственными данными является набор сведений по разным экономическим объектам, но за один и тот же период или момент времени. Примером таких данных явл сведения по разным фирмам (объем производства, численность работников, стоимость основных производственных фондов, прибыль за определенный период и т.д.).
Временными данными является набор сведений, характеризующих один и тот же объект, но в разные периоды или моменты времени. Примером таких данных явл данные о ежемесячных объемах грузооборота порта, о годовых объемах перевезенных грузов судоходной компанией, о среднегодовой себестоимости перевозки одной тонны груза по судоходной компании за ряд лет.
Переменные, участвующие в эконометрической модели, разделяются на следующие виды:
1) текущие экзогенные или независимые переменные (xt), значения которых задаются извне модели на данный момент времени t;
2) текущие эндогенные или зависимые переменные (yt), значения которых определяются внутри модели на данный момент времени t;
3) лаговые (экзогенные (xt-1, xt-2 и т.д.) или эндогенные переменные(yt-1, yt-2 и т.д.)), датированные предыдущими моментами времени и находящиеся в уравнении с текущими переменными;
4) предопределенные (объясняющие) переменные, к которым относятся текущие экзогенные переменные (xt), лаговые экзогенные переменные (xt-1, xt-2 и т.д.), а также лаговые эндогенные переменные (yt-1, yt-2 и т.д.)
Любая эконометрическая модель объясняет значения текущих эндогенных переменных в зависимости от предопределенных переменных.
Похожая информация.




