Что такое доверительный интервал в статистике. Вычисление доверительного интервала в Microsoft Excel
Доверительные интервалы (англ. Confidence Intervals ) одним из типов интервальных оценок используемых в статистике, которые рассчитываются для заданного уровня значимости. Они позволяют сделать утверждение, что истинное значение неизвестного статистического параметра генеральной совокупности находится в полученном диапазоне значений с вероятностью, которая задана выбранным уровнем статистической значимости.
Нормальное распределение
Когда известна вариация (σ 2) генеральной совокупности данных, для расчета доверительных пределов (граничных точек доверительного интервала) может быть использована z-оценка. По сравнению с применением t-распределения, использование z-оценки позволит построить не только более узкий доверительный интервал, но и получить более надежные оценки математического ожидания и среднеквадратического (стандартного) отклонения (σ), поскольку Z-оценка основывается на нормальном распределении.
Формула
Для определения граничных точек доверительного интервала, при условии что известно среднеквадратическое отклонение генеральной совокупности данных, используется следующая формула
| L = X - Z α/2 | σ |
| √n |
Пример
Предположим, что размер выборки насчитывает 25 наблюдений, математическое ожидание выборки равняется 15, а среднеквадратическое отклонение генеральной совокупности составляет 8. Для уровня значимости α=5% Z-оценка равна Z α/2 =1,96. В этом случае нижняя и верхняя граница доверительного интервала составят
| L = 15 - 1,96 | 8 | = 11,864 |
| √25 |
| L = 15 + 1,96 | 8 | = 18,136 |
| √25 |
Таким образом, мы можем утверждать, что с вероятностью 95% математическое ожидание генеральной совокупности попадет в диапазон от 11,864 до 18,136.
Методы сужения доверительного интервала
Допустим, что диапазон является слишком широким для целей нашего исследования. Уменьшить диапазон доверительного интервала можно двумя способами.
- Снизить уровень статистической значимости α.
- Увеличить объем выборки.
Снизив уровень статистической значимости до α=10%, мы получим Z-оценку равную Z α/2 =1,64. В этом случае нижняя и верхняя граница интервала составят
| L = 15 - 1,64 | 8 | = 12,376 |
| √25 |
| L = 15 + 1,64 | 8 | = 17,624 |
| √25 |
А сам доверительный интервал может быть записан в виде
В этом случае, мы можем сделать предположение, что с вероятностью 90% математическое ожидание генеральной совокупности попадет в диапазон .
Если мы хотим не снижать уровень статистической значимости α, то единственной альтернативой остается увеличение объема выборки. Увеличив ее до 144 наблюдений, получим следующие значения доверительных пределов
| L = 15 - 1,96 | 8 | = 13,693 |
| √144 |
| L = 15 + 1,96 | 8 | = 16,307 |
| √144 |
Сам доверительный интервал станет иметь следующий вид
Таким образом, сужение доверительного интервала без снижения уровня статистической значимости возможно только лишь за счет увеличения объема выборки. Если увеличение объема выборки не представляется возможным, то сужение доверительного интервала может достигаться исключительно за счет снижения уровня статистической значимости.
Построение доверительного интервала при распределении отличном от нормального
В случае если среднеквадратичное отклонение генеральной совокупности не известно или распределение отлично от нормального, для построения доверительного интервала используется t-распределение. Это методика является более консервативной, что выражается в более широких доверительных интервалах, по сравнению с методикой, базирующейся на Z-оценке.
Формула
Для расчета нижнего и верхнего предела доверительного интервала на основании t-распределения применяются следующие формулы
| L = X - t α | σ |
| √n |
Распределение Стьюдента или t-распределение зависит только от одного параметра – количества степеней свободы, которое равно количеству индивидуальных значений признака (количество наблюдений в выборке). Значение t-критерия Стьюдента для заданного количества степеней свободы (n) и уровня статистической значимости α можно узнать из справочных таблиц.
Пример
Предположим, что размер выборки составляет 25 индивидуальных значений, математическое ожидание выборки равно 50, а среднеквадратическое отклонение выборки равно 28. Необходимо построить доверительный интервал для уровня статистической значимости α=5%.
В нашем случае количество степеней свободы равно 24 (25-1), следовательно соответствующее табличное значение t-критерия Стьюдента для уровня статистической значимости α=5% составляет 2,064. Следовательно, нижняя и верхняя граница доверительного интервала составят
| L = 50 - 2,064 | 28 | = 38,442 |
| √25 |
| L = 50 + 2,064 | 28 | = 61,558 |
| √25 |
А сам интервал может быть записан в виде
Таким образом, мы можем утверждать, что с вероятностью 95% математическое ожидание генеральной совокупности окажется в диапазоне .
Использование t-распределения позволяет сузить доверительный интервал либо за счет снижения статистической значимости, либо за счет увеличения размера выборки.
Снизив статистическую значимость с 95% до 90% в условиях нашего примера мы получим соответствующее табличное значение t-критерия Стьюдента 1,711.
| L = 50 - 1,711 | 28 | = 40,418 |
| √25 |
| L = 50 + 1,711 | 28 | = 59,582 |
| √25 |
В этом случае мы можем утверждать, что с вероятностью 90% математическое ожидание генеральной совокупности окажется в диапазоне .
Если мы не хотим снижать статистическую значимость, то единственной альтернативой будет увеличение объема выборки. Допустим, что он составляет 64 индивидуальных наблюдения, а не 25 как в первоначальном условии примера. Табличное значение t-критерия Стьюдента для 63 степеней свободы (64-1) и уровня статистической значимости α=5% составляет 1,998.
| L = 50 - 1,998 | 28 | = 43,007 |
| √64 |
| L = 50 + 1,998 | 28 | = 56,993 |
| √64 |
Это дает нам возможность утверждать, что с вероятностью 95% математическое ожидание генеральной совокупности окажется в диапазоне .
Выборки большого объема
К выборкам большого объема относятся выборки из генеральной совокупности данных, количество индивидуальных наблюдений в которых превышает 100. Статистические исследования показали, что выборки большего объема имеют тенденцию быть нормально распределенными, даже если распределение генеральной совокупности отличается от нормального. Кроме того, для таких выборок применение z-оценки и t-распределения дают примерно одинаковые результаты при построении доверительных интервалов. Таким образом, для выборок большого объема допускается применение z-оценки для нормального распределения вместо t-распределения.
Подведем итоги
Доверительный интервал (ДИ; в англ, confidence interval - CI) полученный в исследовании при выборке даёт меру точности (или неопределённости) результатов исследования, для того чтобы делать выводы о популяции всех таких пациентов (генеральная совокупность). Правильное определение 95% ДИ можно сформулировать так: 95% таких интервалов будет содержать истинную величину в популяции. Несколько менее точна такая интерпретация: ДИ - диапазон величин, в пределах которого можно на 95% быть уверенным в том, что он содержит истинную величину. При использовании ДИ акцент делается на определении количественного эффекта, в противоположность величине Р, которая получается в результате проверки статистической значимости. Величина Р не оценивает никакого количества, а служит скорее мерой силы свидетельства против нулевой гипотезы «никакого эффекта». Величина Р сама по себе не говорит нам ничего ни о величине различия, ни даже о его направлении. Поэтому самостоятельные величины Р абсолютно неинформативны в статьях или рефератах. В отличие от них ДИ указывает и на количество эффекта, представляющего непосредственный интерес, например на полезность лечения, и на силу доказательств. Поэтому ДИ непосредственно имеет отношение к практике ДМ.
Подход оценки к статистическому анализу, иллюстрируемый ДИ, направлен на измерение количества интересующего нас эффекта (чувствительность диагностического теста, частота прогнозируемых случаев, сокращение относительного риска при лечении и т.д.), а также на измерение неопределённости в этом эффекте. Чаще всего ДИ - диапазон величин по обе стороны оценки, в котором, вероятно, лежит истинная величина, и можно быть уверенным в этом на 95%. Соглашение использовать 95% вероятность произвольно, также как и величину Р <0,05 для оценки статистической значимости, и авторы иногда используют 90% или 99% ДИ. Заметим, что слово «интервал» означает диапазон величин и поэтому стоит в единственном числе. Две величины, которые ограничивают интервал, называются «доверительными пределами».
ДИ основан на идее, что то же самое исследование, выполненное на других выборках пациентов, не привело бы к идентичным результатам, но что их результаты будут распределены вокруг истинной, однако неизвестной величины. Иными словами, ДИ описывает это как «вариабельность, зависящую от выборки». ДИ не отражает дополнительную неопределённости, обусловленную другими причинами; в частности, он не включает влияние селективной потери пациентов при отслеживании, плохого комплайнса или неточного измерения исхода, отсутствия «ослепления» и т.д. ДИ, таким образом, всегда недооценивает общее количество неопределённости.
Вычисление доверительного интервала
Таблица А1.1. Стандартные ошибки и доверительные интервалы для некоторых клинических измерений
Обычно ДИ вычисляют из наблюдаемой оценки количественного показателя, такого, как различие (d) между двумя пропорциями, и стандартной ошибки (SE) в оценке этого различия. Приблизительный 95% ДИ, получаемый таким образом, - d ± 1,96 SE. Формула изменяется согласно природе меры исхода и охвату ДИ. Например, в рандомизированном плацебо-контролируемом испытании бесклеточной коклюшной вакцины коклюш развивался у 72 из 1670 (4,3%) младенцев, получивших вакцину, и у 240 из 1665 (14,4%) в группе контроля. Различие в процентах, известное как абсолютное снижение риска, составляет 10,1%. SE этого различия равна 0,99%. Соответственно 95% ДИ составляет 10,1% + 1,96 х 0,99%, т.е. от 8,2 до 12,0.
Несмотря на разные философские подходы, ДИ и тесты на статистическую значимость тесно связаны математически.
Таким образом, величина Р «значимая», т.е. Р <0,05 соответствует 95% ДИ, который исключает величину эффекта, указывающую на отсутствие различия. Например, для различия между двумя средними пропорциями это ноль, а для относительного риска или отношения шансов - единица. При некоторых обстоятельствах эти два подхода могут быть не совсем эквивалентны. Преобладающая точка зрения: оценка с помощью ДИ - предпочтительный подход к суммированию результатов исследования, но ДИ и величина Р взаимодополняющи, и во многих статьях используются оба способа представления результатов.
Неопределенность (неточность) оценки, выражаемая в ДИ, в большой степени связана с квадратным корнем из размера выборки. Маленькие выборки предоставляют меньше информации, чем большие, и ДИ соответственно шире в меньшей выборке. Например, статья, сравнивающая характеристики трёх тестов, которые применяются для диагностики инфекции Helicobacter pylori , сообщила о чувствительности дыхательной пробы с мочевиной 95,8% (95% ДИ 75-100). В то время как число 95,8% выглядит внушительно, маленькая выборка из 24 взрослых пациентов с Я. pylori означает, что имеется значительная неопределенность в этой оценке, как показывает широкий ДИ. Действительно, нижний предел 75% намного ниже, чем оценка 95,8%. Если бы такая же чувствительность наблюдалась в выборке 240 человек, то 95% ДИ составлял бы 92,5-98,0, давая больше гарантий, что тест высокочувствителен.
В рандомизированных контролируемых испытаниях (РКИ) незначимые результаты (т.е. те, где Р >0,05) особенно подвержены неверному толкованию. ДИ особенно полезен здесь, поскольку он показывает, насколько совместимы результаты с клинически полезным истинным эффектом. Например, в РКИ, сравнивающем наложение анастомоза швом и скрепками на толстой кишке , раневая инфекция развилась у 10,9% и 13,5% пациентов соответственно (Р = 0,30). 95% ДИ для этого различия составляет 2,6% (от -2 до +8). Даже в этом исследовании, включавшем 652 пациента, остаётся вероятность, что существует умеренное различие в частоте инфекций, возникающих вследствие этих двух процедур. Чем меньше исследование, тем больше неуверенность. Сунг и соавт. выполнили РКИ, чтобы сравнить инфузию октреотида со срочной склеротерапией при остром кровотечении из варикозно-расширенных вен на 100 пациентах. В группе октреотида частота остановки кровотечения составила 84%; в группе склеротерапии - 90%, что даёт Р = 0,56. Заметим, что показатели продолжающегося кровотечения аналогичны таковым при раневой инфекции в упомянутом исследовании. В этом случае, однако, 95% ДИ для различия вмешательств равен 6% (от -7 до +19). Этот интервал весьма широк по сравнению с 5% различием, которое представляло бы клинический интерес. Ясно, что исследование не исключает значительной разницы в эффективности. Поэтому заключение авторов «инфузия октреотида и склеротерапия одинаково эффективны при лечении кровотечения из варикозно-расширенных вен» определённо невалидно. В подобных случаях, когда, как здесь, 95% ДИ для абсолютного снижения риска (АСР; absolute risk reduction - ARR, англ.) включает ноль, ДИ для ЧПЛП (NNT - number needed to treat, англ.) является довольно затруднительным для толкования. ЧПЛП и его ДИ получают из величин, обратных АСР (умножая их на 100, если эти величины даны в виде процентов). Здесь мы получаем ЧПЛП = 100: 6 = 16,6 с 95% ДИ от -14,3 до 5,3. Как видно из сноски «d» в табл. А1.1, этот ДИ включает величины ЧПЛП от 5,3 до бесконечности и ЧПЛВ от 14,3 до бесконечности.
ДИ можно построить для большинства обычно употребляемых статистических оценок или сравнений. Для РКИ он включает разность между средними пропорциями, относительными рисками, отношениями шансов и ЧПЛП. Аналогично ДИ можно получить для всех главных оценок, сделанных в исследованиях точности диагностических тестов - чувствительности, специфичности, прогностической значимости положительного результата (все они являются простыми пропорциями), и отношения правдоподобия - оценок, получаемых в метаанализах и исследованиях типа сравнения с контролем. Компьютерная программа для персональных компьютеров, которая покрывает многие из этих способов использования ДИ, доступна со вторым изданием «Statistics with Confidence». Макросы для вычисления ДИ для пропорций бесплатно доступны для Excel и статистических программ SPSS и Minitab на http://www.uwcm.ac.uk/study/medicine/epidemiology_ statistics/research/statistics/proportions, htm.
Множественные оценки эффекта лечения
В то время как построение ДИ желательно для первичных результатов исследования, они не обязательны для всех результатов. ДИ касается клинически важных сравнений. Например, при сравнении двух групп правилен тот ДИ, что построен для различия между группами, как показано выше в примерах, а не ДИ, который можно построить для оценки в каждой группе. Мало того, что бесполезно давать отдельные ДИ для оценок в каждой группе, это представление может вводить в заблуждение. Точно так же правильный подход при сравнении эффективности лечения в различных подгруппах - сравнение двух (или более) подгрупп непосредственно. Неправильно предполагать, что лечение эффективно только в одной подгруппе, если ее ДИ исключает величину, соответствующую отсутствию эффекта, а другие - нет . ДИ полезны также при сравнении результатов в нескольких подгруппах. На рис. А 1.1 показан относительный риск эклампсии у женщин с преэклампсией в подгруппах женщин из плацебо-контролируемого РКИ сульфата магния.
Рис. А1.2. Лесной график показывает результаты 11 рандомизированных клинических испытаний бычьей ротавирусной вакцины для профилактики диареи в сравнении с плацебо. При оценке относительного риска диареи использован 95% доверительный интервал. Размер чёрного квадрата пропорционален объёму информации. Кроме того, показана суммарная оценка эффективности лечения и 95% доверительного интервала (обозначается ромбом). В метаанализе использована модель случайных эффектов превышает некоторые предварительно установленные; например, это может быть размер, использованный при вычислении величины выборки. В соответствии с более строгим критерием весь диапазон ДИ должен показывать пользу, превышающую предустановленный минимум.
Мы уже обсуждали ошибку, когда отсутствие статистической значимости принимают как указание на то, что два способа лечения одинаково эффективны. Столь же важно не уравнивать статистическую значимость с клинической важностью. Клиническую важность можно предполагать, когда результат статистически значим и величина оценки эффективности лечения
Исследования могут показать, значимы ли результаты статистически и какие из них клинически важны, а какие - нет. На рис. А1.2 приведены результаты четырёх испытаний, для которых весь ДИ <1, т.е. их результаты статистически значимы при Р <0,05 , . После высказанного предположения о том, что клинически важным различием было бы сокращение риска диареи на 20% (ОР = 0,8), все эти испытания показали клинически значимую оценку сокращения риска, и лишь в исследовании Treanor весь 95% ДИ меньше этой величины. Два других РКИ показали клинически важные результаты, которые не были статистически значимыми. Обратите внимание, что в трёх испытаниях точечные оценки эффективности лечения были почти идентичны, но ширина ДИ различалась (отражает размер выборки). Таким образом, по отдельности доказательная сила этих РКИ различна.
Доверительный интервал пришел к нам из области статистики. Это определенный диапазон, который служит для оценки неизвестного параметра с высокой степенью надежности. Проще всего это будет пояснить на примере.
Предположим, нужно исследовать какую-либо случайную величину, например, скорость отклика сервера на запрос клиента. Каждый раз, когда пользователь набирает адрес конкретного сайта, сервер реагирует на это с разной скоростью. Таким образом, исследуемое время отклика имеет случайный характер. Так вот, доверительный интервал позволяет определить границы этого параметра, и затем можно будет утверждать, что с вероятностью в 95% сервера будет находиться в рассчитанном нами диапазоне.
Или же нужно узнать, какому количеству людей известно о торговой марке фирмы. Когда будет подсчитан доверительный интервал, то можно будет, к примеру, сказать что с 95% долей вероятности доля потребителей, знающих о данной находится в диапазоне от 27% до 34%.
С этим термином тесно связана такая величина, как доверительная вероятность. Она представляет собой вероятность того, что искомый параметр входит в доверительный интервал. От этой величины зависит то, насколько большим окажется наш искомый диапазон. Чем большее значение она принимает, тем уже становится доверительный интервал, и наоборот. Обычно ее устанавливают равной 90%, 95% или 99%. Величина 95% наиболее популярна.
На данный показатель также оказывает влияние дисперсия наблюдений и Его определение основано на том предположении, что исследуемый признак подчиняется Это утверждение известно также как Закон Гаусса. Согласно ему, нормальным называется такое распределение всех вероятностей непрерывной случайной величины, которое можно описать плотностью вероятностей. Если предположение о нормальном распределении оказалось ошибочным, то оценка может оказаться неверной.
Сначала разберемся с тем, как вычислить доверительный интервал для Здесь возможны два случая. Дисперсия (степень разброса случайной величины) может быть известна либо нет. Если она известна, то наш доверительный интервал вычисляется с помощью следующей формулы:
хср - t*σ / (sqrt(n)) <= α <= хср + t*σ / (sqrt(n)), где
α - признак,
t - параметр из таблицы распределения Лапласа,
σ - квадратный корень дисперсии.
Если дисперсия неизвестна, то ее можно рассчитать, если нам известны все значения искомого признака. Для этого используется следующая формула:
σ2 = х2ср - (хср)2, где
х2ср - среднее значение квадратов исследуемого признака,
(хср)2 - квадрат данного признака.
Формула, по которой в этом случае рассчитывается доверительный интервал немного меняется:
хср - t*s / (sqrt(n)) <= α <= хср + t*s / (sqrt(n)), где
хср - выборочное среднее,
α - признак,
t - параметр, который находят с помощью таблицы распределения Стьюдента t = t(ɣ;n-1),
sqrt(n) - квадратный корень общего объема выборки,
s - квадратный корень дисперсии.
Рассмотри такой пример. Предположим, что по результатам 7 замеров была определена исследуемого признака, равная 30 и дисперсия выборки, равная 36. Нужно найти с вероятностью в 99% доверительный интервал, который содержит истинное значение измеряемого параметра.
Вначале определим чему равно t: t = t (0,99; 7-1) = 3.71. Используем приведенную выше формулу, получаем:
хср - t*s / (sqrt(n)) <= α <= хср + t*s / (sqrt(n))
30 - 3.71*36 / (sqrt(7)) <= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
Доверительный интервал для дисперсии рассчитывается как в случае с известным средним, так и тогда, когда нет никаких данных о математическом ожидании, а известно лишь значение точечной несмещенной оценки дисперсии. Мы не будем приводить здесь формулы его расчета, так как они довольно сложные и при желании их всегда можно найти в сети.
Отметим лишь, что доверительный интервал удобно определять с помощью программы Excel или сетевого сервиса, который так и называется.
Цель – научить студентов алгоритмам вычисления доверительных интервалов статистических параметров.
При статистической обработке данных вычисленные средняя арифметическая, коэффициент вариации, коэффициент корреляции, критерии различия и другие точечные статистики должны получить количественные границы доверия, которые обозначают возможные колебания показателя в меньшую и большую стороны в пределах доверительного интервала.
Пример
3.1
.
Распределение
кальция в сыворотке крови обезьян, как
было установлено ранее, характеризуется
следующими выборочными показателями:
=
11,94 мг%; =
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней (
=
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней ( )
при доверительной вероятностиP
= 0,95.
)
при доверительной вероятностиP
= 0,95.
Генеральная средняя находится с определенной вероятностью в интервале:
 ,
где
,
где
 –
выборочная средняя арифметическая;t
– критерий Стьюдента;
–
выборочная средняя арифметическая;t
– критерий Стьюдента;
 –
ошибка средней арифметической.
–
ошибка средней арифметической.
По
таблице «Значения критерия Стьюдента»
находим значение
 при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
или
11,69
 12,19
12,19
Таким образом, с вероятностью 95%, можно утверждать, что генеральная средняя данного нормального распределения находится между 11,69 и 12,19 мг%.
Пример
3.2
. Определите
границы 95%-ного доверительного интервала
для генеральной дисперсии ( )
распределения кальция в крови обезьян,
если известно, что
)
распределения кальция в крови обезьян,
если известно, что =
1,60, приn
= 100.
=
1,60, приn
= 100.
Для решения задачи можно воспользоваться следующей формулой:
Где
 –
статистическая ошибка дисперсии.
–
статистическая ошибка дисперсии.
Находим
ошибку выборочной дисперсии по формуле:
 .
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
.
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
Воспользуемся формулой и получим:
или
1,38
 1,82
1,82
Более
точно доверительный интервал генеральной
дисперсии можно построить с применением
 (хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия
(хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле
для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле ,
для верхней –
,
для верхней – .
Например, для доверительного уровня
.
Например, для доверительного уровня =
0,99
=
0,99 = 0,010,
= 0,010, =
0,990. Соответственно по таблице распределения
критических значений
=
0,990. Соответственно по таблице распределения
критических значений ,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
 и
и .
Получаем
.
Получаем равно 135,80, а
равно 135,80, а равно70,06.
равно70,06.
Чтобы
найти доверительные границы генеральной
дисперсии с помощью
 воспользуемся
формулами: для нижней границы
воспользуемся
формулами: для нижней границы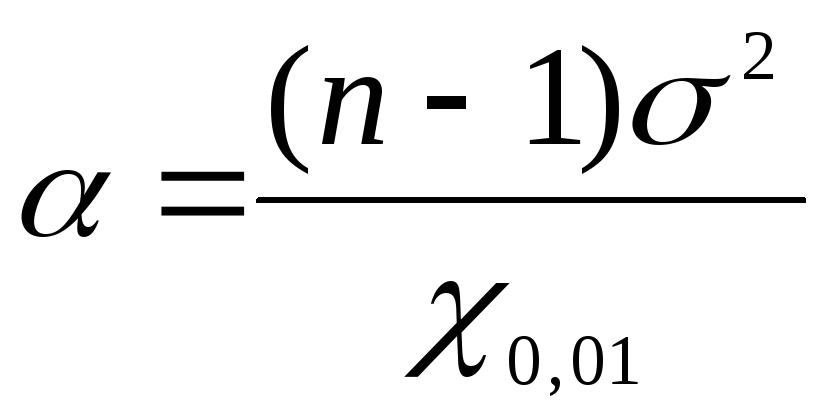 ,
для верхней границы
,
для верхней границы .
Подставим данные задачи найденные
значения
.
Подставим данные задачи найденные
значения в
формулы:
в
формулы: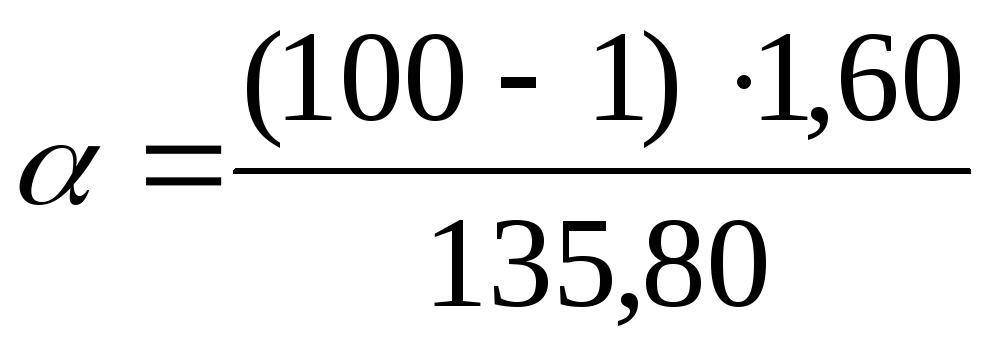 =
1,17;
=
1,17; =
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
=
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
Пример 3.3 . Среди 1000 семян пшеницы из поступившей на элеватор партии обнаружено 120 семян зараженных спорыньей. Необходимо определить вероятные границы генеральной доли зараженных семян в данной партии пшеницы.
Доверительные границы для генеральной доли при всех возможных ее значениях целесообразно определять по формуле:
 ,
,
Где n – число наблюдений; m – абсолютная численность одной из групп; t – нормированное отклонение.
Выборочная
доля зараженных семян равна
 или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Подставляем имеющиеся данные в формулу:
Отсюда
границы доверительного интервала
равны =
0,122–0,041 = 0,081, или 8,1%;
=
0,122–0,041 = 0,081, или 8,1%; = 0,122 + 0,041 = 0,163, или 16,3%.
= 0,122 + 0,041 = 0,163, или 16,3%.
Таким образом, с доверительной вероятностью 95% можно утверждать, что генеральная доля зараженных семян находится между 8,1 и 16,3%.
Пример 3.4 . Коэффициент вариации, характеризующий варьирование кальция (мг%) в сыворотке крови обезьян, оказался равным 10,6%. Объем выборки n = 100. Необходимо определить границы 95%-ного доверительного интервала для генерального параметра Cv .
Границы доверительного интервала для генерального коэффициента вариации Cv определяются по следующим формулам:
 и
и
 ,
гдеK
промежуточная
величина, вычисляемая по формуле
,
гдеK
промежуточная
величина, вычисляемая по формуле
 .
.
Зная,
что при доверительной вероятности Р
= 95% нормированное отклонение (критерий
Стьюдента при k
=
 )t
= 1,960,
предварительно рассчитаем величину К:
)t
= 1,960,
предварительно рассчитаем величину К:
 .
.
 или
9,3%
или
9,3%
 или
12,3%
или
12,3%
Таким образом, генеральный коэффициент вариации с доверительной вероятностью 95% лежит в интервале от 9,3 до 12,3%. При повторных выборках коэффициент вариации не превысит 12,3% и не окажется ниже 9,3% в 95 случаях из 100.
Вопросы для самоконтроля:

Задачи для самостоятельного решения.
1. Средний процент жира в молоке за лактацию коров холмогорских помесей был следующим: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Установите доверительные интервалы для генеральной средней при доверительной вероятности 95% (20 баллов).
2. На 400 растениях гибридной ржи первые цветки появились в среднем на 70,5 день после посева. Среднее квадратическое отклонение было 6,9 дня. Определите ошибку средней и доверительные интервалы для генеральной средней и дисперсии при уровне значимости W = 0,05 и W = 0,01 (25 баллов).
3.
При изучении длины листьев 502 экземпляров
садовой земляники были получены следующие
данные:
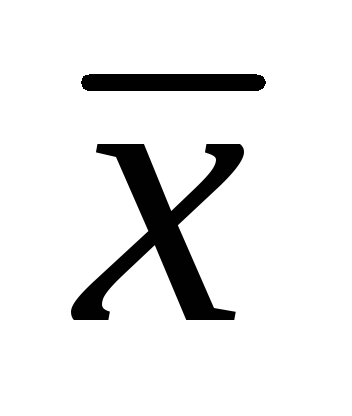 = 7,86 см; σ
= 1,32 см,
= 7,86 см; σ
= 1,32 см,
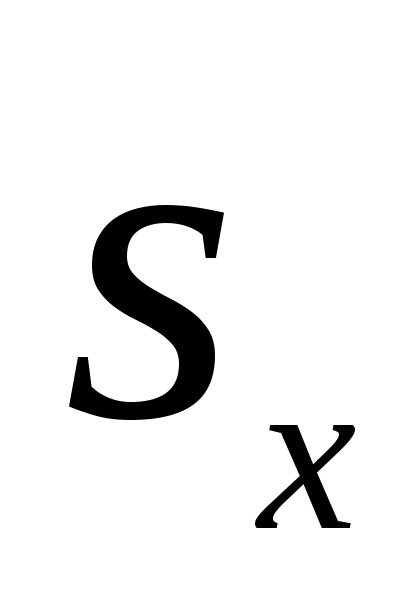 =± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
=± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
4. При обследовании 150 взрослых мужчин средний рост был равен 167 см, а σ = 6 см. В каких пределах находится генеральная средняя и генеральная дисперсия с доверительной вероятностью 0,99 и 0,95? (25 баллов).
5.
Распределение кальция в сыворотке крови
обезьян характеризуется следующими
выборочными показателями:
 = 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
= 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
6. Было изучено общее содержание азота в плазме крови крыс-альбиносов в возрасте 37 и 180 дней. Результаты выражены в граммах на 100 см 3 плазмы. В возрасте 37 дней 9 крыс имели: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. В возрасте 180 дней 8 крыс имели: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Установите доверительные интервалы для разницы с доверительной вероятностью 0,95 (50 баллов).
7. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения кальция (мг%) в сыворотке крови обезьян, если для этого распределения объем выборки n = 100, статистическая ошибка выборочной дисперсии s σ 2 = 1,60 (40 баллов).
8. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения 40 колосков пшеницы по длине (σ 2 = 40, 87 мм 2). (25 баллов).
9. Курение считают основным фактором, предрасполагающим к обструктивным заболеваниям легких. Пассивное курение таким фактором не считается. Ученые усомнились в безвредности пассивного курения и исследовали проходимость дыхательных путей у некурящих, пассивных и активных курильщиков. Для характеристики состояния дыхательных путей взяли один из показателей функции внешнего дыхания – максимальную объемную скорость середины выдоха. Уменьшение этого показателя – признак нарушения проходимости дыхательных путей. Данные обследования приведены в таблице.
|
Число обследованных |
Максимальная объемная скорость середины выдоха, л/с |
||
|
Стандартное отклонение |
|||
|
Некурящие |
|||
|
работают в помещении, где не курят | |||
|
работают в накуренном помещении | |||
|
Курящие |
|||
|
выкуривающие небольшое число сигарет | |||
|
выкуривающие среднее число сигарет | |||
|
выкуривающие большое число сигарет | |||
По данным таблицы найдите 95% доверительные интервалы для генеральной средней и генеральной дисперсии для каждой из групп. В чем заключаются различия между группами? Результаты представьте графически (25 баллов).
10. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной дисперсии численности поросят в 64 опоросах, если статистическая ошибка выборочной дисперсии s σ 2 = 8, 25 (30 баллов).
11. Известно, что средняя масса кроликов составляет 2,1 кг. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной средней и дисперсии при n = 30, σ = 0,56 кг (25 баллов).
12.
У 100 колосьев измеряли озерненность
колоса (Х
),
длину колоса (Y
)
и массу зерна в колосе (Z
).
Найти доверительные интервалы для
генеральной средней и дисперсии при P
1
= 0,95, P
2
= 0,99, P
3
= 0,999, если
 = 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
= 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
13.
В отобранных случайным образом 100
колосьях озимой пшеницы подсчитывалось
число колосков. Выборочная совокупность
характеризовалась следующими показателями:
 = 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат (
= 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат ( )
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
)
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
14. Число ребер на раковинах ископаемого моллюска Orthambonites calligramma :
Известно, что n = 19, σ = 4,25. Определите границы доверительного интервала для генеральной средней и генеральной дисперсии при уровне значимости W = 0,01 (25 баллов).
15. Для определения удоев молока на молочно-товарной ферме ежедневно определялась продуктивность 15 коров. По данным за год каждая корова давала в среднем в сутки следующее количество молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Постройте доверительные интервалы для генеральной дисперсии и средней арифметической. Можно ли ожидать, что среднегодовой удой на каждую корову составит 10000 литров? (50 баллов).
16. С целью определения урожая пшеницы в среднем по агрохозяйству были проведены укосы на пробных участках площадью 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 и 2 га. Урожайность (ц/га) с участков составила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 соответственно. Постройте доверительные интервалы для генеральных дисперсии и средней арифметической. Можно ли ожидать, что в среднем по агрохозяйству урожай составит 42 ц/га? (50 баллов).
Доверительные интервалы.
Вычисление доверительного интервала базируется на средней ошибке соответствующего параметра. Доверительный интервал показывает, в каких пределах с вероятностью (1-a) находится истинное значение оцениваемого параметра. Здесь a – уровень значимости, (1-a) называют также доверительной вероятностью.
В первой главе мы показали, что, например, для среднего арифметического, истинное среднее по совокупности примерно в 95% случаев лежит в пределах 2 средних ошибок среднего. Таким образом, границы 95% доверительного интервала для среднего будет отстоять от выборочного среднего на удвоенную среднюю ошибку среднего, т.е. мы умножаем среднюю ошибку среднего на некий коэффициент, зависящий от доверительной вероятности. Для среднего и разности средних берётся коэффициент Стьюдента (критическое значение критерия Стьюдента), для доли и разности долей критическое значение критерия z. Произведение коэффициента на среднюю ошибку можно назвать предельной ошибкой данного параметра, т.е. максимальную, которую мы можем получить при его оценке.
Доверительный интервал для среднего арифметического : .
Здесь - выборочное среднее;
Средняя ошибка среднего арифметического;
s – выборочное среднее квадратическое отклонение;
n
f = n -1 (коэффициент Стьюдента).
Доверительный интервал для разности средних арифметических :
Здесь - разность выборочных средних;
 - средняя ошибка разности средних арифметических;
- средняя ошибка разности средних арифметических;
s 1 ,s 2 – выборочные средние квадратические отклонения;
n 1 ,n 2
Критическое значение критерия Стьюдента при заданных уровне значимости a и числе степеней свободы f=n 1 +n 2 -2 (коэффициент Стьюдента).
Доверительный интервал для доли :
![]() .
.
Здесь d – выборочная доля;
– средняя ошибка доли;
n – объём выборки (численность группы);
Доверительный интервал для разности долей :
Здесь - разность выборочных долей;
 – средняя ошибка разности средних арифметических;
– средняя ошибка разности средних арифметических;
n 1 ,n 2 – объёмы выборок (численности групп);
Критическое значение критерия z при заданном уровне значимости a ( , , ).
Вычисляя доверительные интервалы для разности показателей, мы, во-первых, непосредственно видим возможные значения эффекта, а не только его точечную оценку. Во-вторых, можем сделать вывод о принятии или опровержении нулевой гипотезы и, в-третьих, можем сделать вывод о мощности критерия.
При проверке гипотез с помощью доверительных интервалов надо придерживаться следующего правила:
Если 100(1-a)-процентный доверительный интервал разности средних не содержит нуля, то различия статистически значимы на уровне значимости a; напротив, если этот интервал содержит ноль, то различия статистически не значимы.
Действительно, если этот интервал содержит ноль, то, значит, сравниваемый показатель может оказаться как больше, так и меньше в одной из групп, по сравнению с другой, т.е. наблюдаемые различия случайны.
По месту, где находится ноль внутри доверительного интервала, можно судить о мощности критерия. Если ноль близок к нижней или верхней границе интервала, то возможно при большей численности сравниваемых групп, различия достигли бы статистической значимости. Если ноль близок к середине интервала, то, значит, равновероятно и увеличение и уменьшение показателя в экспериментальной группе, и, вероятно, различий действительно нет.
Примеры:
Сравнить операционную летальность при применении двух разных видов анестезии: с применением первого вида анестезии оперировалось 61 человек, умерло 8, с применением второго – 67 человек, умерло 10.
d 1 = 8/61 = 0,131; d 2 = 10/67 = 0,149; d1-d2 = - 0,018.
Разность летальностей сравниваемых методов будет находиться в интервале (-0,018 - 0,122; -0,018 + 0,122) или (-0,14 ; 0,104) с вероятностью 100(1-a) = 95%. Интервал содержит ноль, т.е. гипотезу об одинаковой летальности при двух разных видах анестезии отвергнуть нельзя.
Таким образом, летальность может и уменьшится до 14% и увеличиться до 10,4% с вероятностью 95%, т.е. ноль находится примерно по середине интервала, поэтому можно утверждать, что, скорее всего, действительно не отличаются по летальности эти два метода.
В рассмотренном ранее примере сравнивалось среднее время нажатия при теппинг-тесте в четырёх группах студентов, отличающихся по экзаменационной оценке. Вычислим доверительные интервалы среднего времени нажатия для студентов, сдавших экзамен на 2 и на 5 и доверительный интервал для разности этих средних.
Коэффициенты Стьюдента находим по таблицам распределения Стьюдента (см. приложение): для первой группы: = t(0,05;48) = 2,011; для второй группы: = t(0,05;61) = 2,000. Таким образом, доверительные интервалы для первой группы: = (162,19-2,011*2,18 ; 162,19+2,011*2,18) = (157,8 ; 166,6) , для второй группы (156,55-2,000*1,88 ; 156,55+2,000*1,88) = (152,8 ; 160,3). Итак, для сдавших экзамен на 2, среднее время нажатия лежит в пределах от 157,8 мс до 166,6 мс с вероятностью 95%, для сдавших экзамен на 5 – от 152,8 мс до 160,3 мс с вероятностью 95%.
Проверять нулевую гипотезу можно и по доверительным интервалам для средних, а не только для разности средних. Например, как в нашем случае, если доверительные интервалы для средних перекрываются, то нулевую гипотезу отвергнуть нельзя. Для того чтобы отвергнуть гипотезу на выбранном уровне значимости, соответствующие доверительные интервалы не должны перекрываться.
Найдём доверительный интервал для разности среднего времени нажатия в группах сдавших экзамен на 2 и на 5. Разность средних: 162,19 – 156,55 = 5,64. Коэффициент Стьюдента: = t(0,05;49+62-2) = t(0,05;109) = 1,982. Групповые средние квадратические отклонения будут равны: ; . Вычисляем среднюю ошибку разности средних: . Доверительный интервал: =(5,64-1,982*2,87 ; 5,64+1,982*2,87) = (-0,044 ; 11,33).
Итак, разница среднего времени нажатия в группах, сдавших экзамен на 2 и на 5, будет находиться в интервале от -0,044 мс до 11,33 мс. В этот интервал входит ноль, т.е. среднее время нажатия у отлично сдавших экзамен, может и увеличиться и уменьшится по сравнению с неудовлетворительно сдавшими, т.е. нулевую гипотезу отвергнуть нельзя. Но ноль находится очень близко к нижней границе, время нажатия гораздо вероятнее всё-таки уменьшается у отлично сдавших. Таким образом, можно сделать вывод, что различия в среднем времени нажатия между сдавшими на 2 и на 5 всё-таки есть, просто мы не смогли их обнаружить при данном изменении среднего времени, разбросе среднего времени и объёмах выборок.
Мощность критерия – это вероятность отвергнуть неверную нулевую гипотезу, т.е. найти различия там, где они действительно есть.
Мощность критерия определяется исходя из уровня значимости, величины различий между группами, разброса значений в группах и объёма выборок.
Для критерия Стьюдента и дисперсионного анализа можно воспользоваться диаграммами чувствительности.
Мощность критерия можно использовать при предварительном определении необходимой численности групп.
Доверительный интервал показывает, в каких пределах с заданной вероятностью находится истинное значение оцениваемого параметра.
С помощью доверительных интервалов можно проверять статистические гипотезы и делать выводы о чувствительности критериев.
ЛИТЕРАТУРА.
Гланц С. – Глава 6,7.
Реброва О.Ю. – с.112-114, с.171-173, с.234-238.
Сидоренко Е. В. – с.32-33.
Вопросы для самопроверки студентов.
1. Что такое мощность критерия?
2. В каких случаях необходимо оценить мощность критериев?
3. Способы расчёта мощности.
6. Как проверить статистическую гипотезу с помощью доверительного интервала?
7. Что можно сказать о мощности критерия при расчёте доверительного интервала?
Задачи.




